

Engagement Bait

In This Article...
- Engagement Bait
- Best Time Ever
- The Beatings Shall Go On...
- Rank Modifying Spammers
- Gray Areas & Market Edges
- Facts & Figures
- No Site is an Island
- High Value Traffic vs Highly Engaged Traffic
- I Just Want to Make Money. Period. Exclamation Point!
- Panda & SEO Blogs
- Engagement as the New Link Building
- How Engagement is Not Like Links
- Change the Business Model
- Put Engagement Front and Center
Engagement Bait
Best Time Ever
If one is an optimist about techno-utopia, it is easy to argue there has never been a better time to start something, as the web keeps getting more powerful and complex. The problem with that view is the barrier to entry may rise faster than technology progresses leading to fewer business opportunities as markets consolidate and business dynamism slows down. Hosting is dirt cheap and Wordpress is a powerful CMS which is free. But the cost of keeping sites secured goes up over time & the cost of building something to a profitable scale keeps increasing.
Google is still growing quickly in emerging markets, but they can't monetize those markets well due to under-developed ad ecosystems. And as Google has seen their revenue growth rate slow, they've slowed hiring and scrubbed an increasing share of publisher ad clicks to try to shift more advertiser budget onto Google.com and YouTube.com. They've also ramped up brand-related bid prices in search (RKG pegged the YoY shift at 39% higher & QoQ at 10% higher). Those brand-bids arbitrage existing brand equity and people using last click attribution under-credit other media buys.
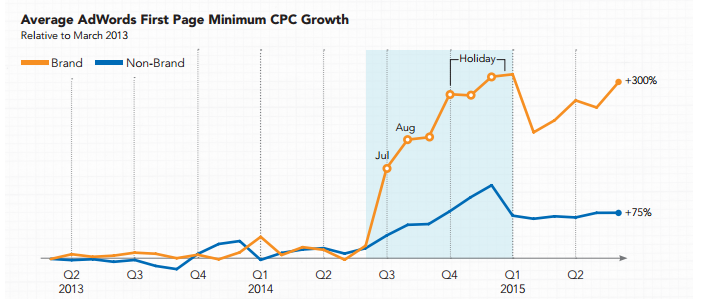
The Beatings Shall Go On...
Brands have brand equity to protect, which Google can monetize. So long as Google can monetize the brand-related queries, it doesn't hurt Google to over-represent brands on other search queries. It is a low-risk move for Google since users already have an affinity for the associated brands. And as Google over-promotes brands across a wider array of search queries, Google can increase the AdWords click costs on branded keywords for brands which want to protect their brand terms:
Several different marketing agencies are claiming the price of branded cost-per-click Google AdWords has ballooned by as much as 141% in the last four to eight weeks, causing speculation to swirl throughout the industry.
New sites are far riskier to rank. They have no engagement metrics and no consumer awareness. If Google ranks a garbage page on a brand site users likely blame the brand. If Google ranks a garbage smaller site users likely blame Google. Until you build exposure via channels other than organic search, it can be hard to break into the organic search market as Google increasingly takes a wait-and-see approach.
It is no secret that as Google's growth rate has slowed they've become more abusive to the webmaster community. Increasing content theft, increasing organic search result displacement (via additional whitespace, larger ad extensions, more vertical search types), more arbitrary penalties, harsher penalties, longer penalties, irregular algorithm updates, etc.
If you are not funded by Google, anything that can be a relevancy signal can also be proof of intent to spam. But those who have widespread brand awareness and great engagement metrics do not need to be as aggressive with links or anchor text to rank. So they have more positive ranking signals created through their engagement metrics, have more clean links to offset any of the less clean links they build, are given a greater benefit of the doubt on manual review, and on the rare chance they are penalized they recover more quickly.
Further, those who get the benefit of the doubt do not have to worry about getting torched by ancillary anti-revenue directives. A smaller site has to worry about being too "ad heavy" but a trusted site like Forbes can run interstitial ads, YouTube can run pre-roll ads, and The Verge can run ads requiromg a scroll to see anything beyond the welcome ad and the site's logo - while having a lower risk profile than the smaller site.

Bigger sites get subsidies while smaller sites get scrubbed.
The real risk for bigger players is not the algorithm but the search interface. While marketers study the potential impacts of a buy button on mobile devices, Google is quietly rolling out features that will allow them to outright displace retailers by getting information directly from manufacturers.
Rank Modifying Spammers
Google is willing to cause massive collateral damage to harm others and has been that way since at least 2005:
I was talking to a search rep about Google banning certain sites for no reason other than the fact that a large number of spammers where using that sTLD, well 1.2 million small business got washed down the plug hole with that tweak ! On the other side of the coin I discussed with Yahoo about banning sites, when they ban a site they should still list the homepage if someone typed in the url. Even if Yahoo thought that the site in question as complete waste of bandwidth, if a searcher wanted to find that site they should still be able to find it !! That’s a search engines job at heart to supply the public with relevant search results.
And one could argue that same sort of "throw the baby out with the bathwater" has not only continued with Panda false positives, pre-emptive link disavows, etc. but that it spanned all the way back to the Florida update of 2003.
On Twig Matt Cutts stated:
There are parts of Google's algorithms specifically designed to frustrate spammers and mystify them and make them frustrated. And some of the stuff we do gives people a hint their site is going to drop and then a week or two later their site actually does drop so they get a little bit more frustrated. And so hopefully, and we've seen this happen, people step away from the dark side and say "you know, that was so much pain and anguish and frustration, let's just stay on the high road from now on" some of the stuff I like best is when people say "you know this SEO stuff is too unpredictable, I'm just going to write some apps. I'm going to go off and do something productive for society." And that's great because all that energy is channeled at something good.
Both Bill Slawski and PeterD wrote about a Google patent related to "rank modifying spammers" named Ranking Documents. At the core of this patent is the idea that Google is really good at pissing people off, screwing with people, and destroying the ability of SEOs to effectively & profitably deliver services to clients.
The abstract from the patent reads:
A system determines a first rank associated with a document and determines a second rank associated with the document, where the second rank is different from the first rank. The system also changes, during a transition period that occurs during a transition from the first rank to the second rank, a transition rank associated with the document based on a rank transition function that varies the transition rank over time without any change in ranking factors associated with the document.
Here are a couple images from the patent. First an image of what a transparent & instantaneous rank adjustment might look like
![]()
And then a couple examples of alternative models of rank transition.
![]()
The basic problem Google has with instantaneous rank shifts is it would let "spammers" know what they are doing is working & effective. Whereas if Google puts in a bit of delay, they make it much harder to be certain if what was done worked. And, better yet (for Google), if they first make the rank drop before letting it go up, they then might cause people to undo their investments, revert their strategy, and/or cause communications issues between the SEO & client - ultimately leading to the client firing the SEO. This is literally the stated goal of this patent: to track how marketers respond to anomalies in order to self-identify them as spammers so they may be demoted & to cause client communication issues.
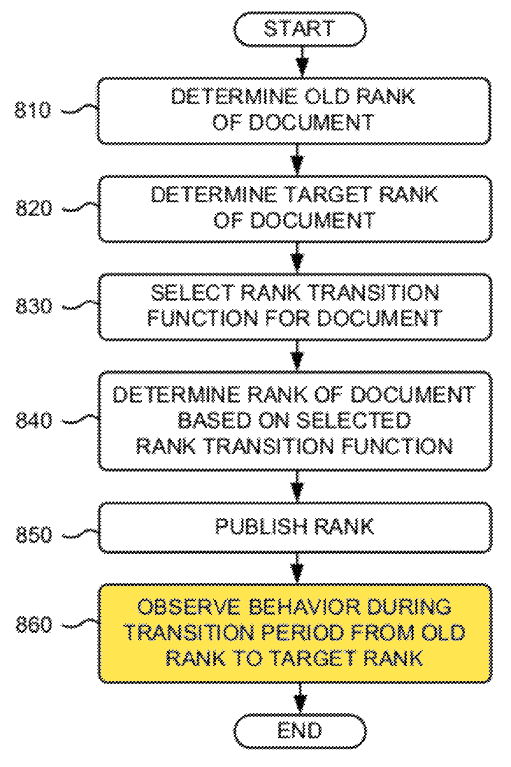
By artificially inflating the rankings of certain (low quality or unrelated) documents, rank-modifying spamming degrades the quality of the search results. Systems and methods consistent with the principles of the invention may provide a rank transition function (e.g., time-based) to identify rank-modifying spammers. The rank transition function provides confusing indications of the impact on rank in response to rank-modifying spamming activities. The systems and methods may also observe spammers' reactions to rank changes caused by the rank transition function to identify documents that are actively being manipulated. This assists in the identification of rank-modifying spammers.
The "noise" offered by the above process can also be mixed up to prevent itself from offering a consistent signal & pattern:
Based on the knowledge that search results are consciously being manipulated (e.g., frequently monitored and controlled) via rank-modifying spamming, search engine 430 may, as described in more detail below, use a rank transition function that is dynamic in nature. For example, the rank transition function may be time-based, random, and/or produce unexpected results.
And what happens during that noise period?
For example, the initial response to the spammer's changes may cause the document's rank to be negatively influenced rather than positively influenced. Unexpected results are bound to elicit a response from a spammer, particularly if their client is upset with the results. In response to negative results, the spammer may remove the changes and, thereby render the long-term impact on the document's rank zero. Alternatively or additionally, it may take an unknown (possibly variable) amount of time to see positive (or expected) results in response to the spammer's changes. In response to delayed results, the spammer may perform additional changes in an attempt to positively (or more positively) influence the document's rank. In either event, these further spammer-initiated changes may assist in identifying signs of rank-modifying spamming.
Think of the time delay in the above rank shift as being a parallel to keyword (not provided) or how Google sometimes stacks multiple algorithm updates on top of one another in order to conceal the impact of any individual update. And the whole time things are in flux, Google may watch the SEO's response in order to profile and penalize them:
the delayed and/or negative response to the rank-modifying spamming may cause the spammer to take other measures to correct it. For example, for a delayed response, the spammer may subject the document to additional rank-modifying spamming (e.g., adding additional keywords, tiny text, invisible text, links, etc.). For a negative response, the spammer may revert the document and/or links to that document (or other changes) to their prior form in an attempt to undo the negative response caused by the rank-modifying spamming.
The spammer's behavior may be observed to detect signs that the document is being subjected to rank-modifying spamming (block 860). For example, if the rank changed opposite to the initial 10% change, then this may correspond to a reaction to the initially-inverse response transition function. Also, if the rank continues to change unexpectedly (aside from the change during the transition period due to the rank transition function), such as due to a spammer trying to compensate for the undesirable changes in the document's rank, then this would be a sign that the document is being subjected to rank-modifying spamming.
Correlation can be used as a powerful statistical prediction tool. In the event of a delayed (positive) rank response, the changes made during the delay period that impact particular documents can be identified. In the event of a negative initial rank response, correlation can be used to identify reversion changes during the initial negative rank response. In either case, successive attempts to manipulate a document's rank will be highlighted in correlation over time. Thus, correlation over time can be used as an automated indicator of rank-modifying spam.
When signs of rank-modifying spamming exist, but perhaps not enough for a positive identification of rank-modifying spamming, then the “suspicious” document may be subjected to more extreme rank variations in response to changes in its link-based information. Alternatively, or additionally, noise may be injected into the document's rank determination. This noise might cause random, variable, and/or undesirable changes in the document's rank in an attempt to get the spammer to take corrective action. This corrective action may assist in identifying the document as being subjected to rank-modifying spamming.
If the document is determined to be subjected to rank-modifying spamming, then the document, site, domain, and/or contributing links may be designated as spam. This spam can either be investigated, ignored, or used as contra-indications of quality (e.g., to degrade the rank of the spam or make the rank of the spam negative).
Google can hold back trust and screw with the data on individual documents, or do it sitewide:
In one implementation, a rank transition function may be selected on a per-document basis. In another implementation, a rank transition function may be selected for the domain/site with which the document is associated, the server on which the document is hosted, or a set of documents that share a similar trait (e.g., the same author (e.g., a signature in the document), design elements (e.g., layout, images, etc.), etc.). In any of these situations, the documents associated with the domain/site/set or hosted by the same server may be subjected to the same rank transition function. In yet another implementation, a rank transition function may be selected randomly. In a further implementation, if a document is identified as “suspicious” (described below), a different rank transition function may be selected for that document.
Part of the "phantom update," which started on April 29th of 2015, appeared to be related to allowing some newer sites to accrue trust and rank, or relaxing the above sort of dampening factor for many sites. Google initially denied the update even happening & only later confirmed it.
So long as you are not in the top 10 results, then it doesn't really matter to Google if you rank 11, 30, 87, or 999. They can arbitrarily adjust ranks for any newer site or any rapidly changing page/site which doesn't make it to page 1. Doing so creates massive psychological impacts and communication costs to people focused on SEO, while it costs Google nothing & other "real" publishers (not focused primarily on SEO) nothing.
If you are an individual running your own sites & it takes 6 months to see any sort of positive reaction to your ranking efforts then you only have to justify the time delay & funding the SEO efforts to yourself. But if you are working on a brand new client site & it has done nothing for a half-year the odds of the client firing you are extremely high (unless they have already worked with you in the past on other projects). And then if the rankings kick in a month or two after the client fires you then the client might think your work is what prevented the site from ranking rather than it being what eventually allowed the site to rank. That client will then have a damaged relationship with the SEO industry forever. They'll likely chronically under-invest in SEO, only contact an SEO after things are falling apart, and then be over-reactive to any shifts during the potential recovery process.
The SEO game is literally dominated by psychological warfare.
Gray Areas & Market Edges
Many leading online platforms will advocate putting the user first, but they will often do the opposite of what they suggest is a best practice for others.
Google says stop pushing App downloads yet its own teams push apps using same "bad" designs. http://t.co/9Z3NeGbZxR pic.twitter.com/UzX9DbKn3x— Jeremy Stoppelman (@jeremys) July 24, 2015
Once an entity has market power it gets to dictate the terms of engagement. But newer platforms with limited funding don't have that luxury. They must instead go to a market edge (which is ignored or under-served by existing players), build awareness, and then spread across to broader markets.
- Yelp never would have succeeded if it launched nationwide or globally from the start. They started in the Bay Area, proved the model, then expanded.
- Mark Zuckerberg accessed some Harvard information without permission to seed his site. And Facebook was started on a dense college campus before spreading to broader markets.
- Social networks often look the other way on spam when they are smaller because usage and adoption metrics fuel (perceived) growth, which in turn fuels a higher valuation from venture capital investors. Then they later clean up the spam and take a hit shortly before or after they go public.
- Pinterest allowed affiliate links and then banned them overnight.
- PlentyOfFish was accused of scraping profile information from other dating sites.
- Uber and AirBnB didn't pay much attention to many local laws until after they had significant marketshare. AirBnB built much of their early exposure off of Craigslist.
- Reddit was able to grow to a huge scale by serving some sketchy markets like jailbait, racist stuff, and other "industries" which were not well served online. Then when the site attained serious scales the founders came back and were all about building policies to protect users & promoting the message that the site is not about free speech at any cost.
- Google's business model relied on violating Overture's search ad patents. When they were profitable and about to go public they gave Yahoo!/Overture some stock to settle the lawsuit. In mobile they violated patents, then bought and gutted Motorola to offset it.
- YouTube's founders fueled their early growth by uploading pirated video content. When the site attained serious scale Google signed deals with the music labels and implemented Content ID.
- Alibaba sold a lot of counterfeit goods & didn't push to significantly clean it up until after they were a publicly listed $200 billion company.
The above is not advocacy for crime, but rather to point to the fact that even the biggest successes online had to operate in gray areas at some point in order to create large ecosystems. If you are trying to build something from nothing, odds are fairly good you will have to at some point operate in a gray area of some sort. If not a legal gray area, then perhaps by not following some other entity's guidelines or terms of services. Some guidelines exist to protect people, but many of them exist purely for anti-competitive reasons. As you become more successful, someone will hate you & there is likely someone or something you will hate. There is always an enemy.
Almost nobody spends as much as Google does on lobbying. And almost no company in recent history has been sued as many times as Google has.
I wouldn't suggest one should try to manufacture signals without also trying to build something of substance, but if you are starting from scratch and build something of substance without pushing hard to create some of the signals the odds of it working out are quite low. In most cases, if you build it, they won't come - unless it is aggressively marketed.
Facts & Figures
Google published a research paper named Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources. Some SEOs who read that research paper thought Google was suggesting links could be replaced with evaluating in-content facts as a new backbone of search relevancy. Rather I read that paper as Google suggesting what websites they would prefer to steal content from to power their knowledge graph.
Including stats and facts in content are important. They make the content easy to cite by journalists & by other people who are quickly writing while wanting to have their content come across as well-researched rather than a fluffy opinion piece. And it makes it easier for people to repeatedly seek out a source if they know that source can give them a more in-depth background on a particular topic. For example, when I sometimes buy Japanese video games on Yahoo! Japan auctions through Buyee, I might get the localized version of the name from HardcoreGaming101.net or Wikipedia.org.
But facts alone are not enough. By the time something is an irrefutable fact, it's ability to act as a sustainable differentiator on its own approaches zero & parasites like Google scrape away the value. Google didn't have to bear the cost of vetting the following, but the person who did isn't cited.
And even in some cases where they are cited, much of the value is extracted.
Choose shoes wisely. ... pic.twitter.com/YLBtaHWare— Carl Hendy (@carlhendy) July 30, 2015
As much as we like to view ourselves as rational human beings, everyone likes some form of gossip. It is obvious sites like TMZ and PerezHilton.com trade in gossip and speculation. But that sort of activity doesn't end with celebrity sites. Most sites which are successful on a sustainable basis tend to go beyond facts. Think of your favorite sites you regularly read. My favorite blogs related to hobbies like collecting vintage video games and sports cards are highly opinionated sites. And on this site we present many facts and figures, but a large amount of the value of this site is driven by speculating the "why" behind various trends and predicting the forward trends.
And as mainstream media sources are having their economics squeezed by the web, even some of them are openly moving "beyond facts." Consider the following quote from Margaret Sullivan, the public editor from the New York Times:
I often hear from readers that they would prefer a straight, neutral treatment — just the facts. But The Times has moved away from that, reflecting editors’ reasonable belief that the basics can be found in many news outlets, every minute of the day. They want to provide “value-added” coverage.
A good example of their "value-added" coverage was an entirely inaccurate exposé on nail salons. Even the most trusted news organizations are becoming more tabloid by the day, with the success of tabloids being used as a "case study" of a model other news organizations should follow.
No Site is an Island
One of the key points from the Cluetrain Manifesto was Hyperlinks subvert Hierarchies. The power of the web is driven largely by the connections between documents.
Sites which don't cite sources (or do not link to them) are inviting searches to go back to Google and look for more information. And, quite often, that will happen through a short click (a negative user engagement signal).
When Google was collecting less end user data (or folding it into their relevancy algorithms less aggressively) trying to maximally monetize all traffic was a rational approach for a webmaster. You only had to get the traffic to your site. What the traffic did after it hit your site wasn't all that important beyond dollars and cents, so long as you had links as the proxy for relevancy. But in a world where engagement metrics are on an equal footing with links and short clicks can count against you, it can make sense to under-monetize some of your traffic and give users other potential destinations to seek out. Users who click forward into another site are not clicking back to the Google search results. They are long clicks and a win.
Bill Slawski reviewed a Google patent named Determining Reachability. The patent abstract reads:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for determining a resource's reachability score. In one aspect, a method includes identifying one or more secondary resources reachable through one or more links of a primary resource wherein the secondary resources are within a number of hops from the primary resource; determining an aggregate score for the primary resource based on respective scores of the secondary resources wherein each one of the respective scores is calculated based on prior user interactions with a respective secondary resource; and providing the aggregate score as an input signal to a resource ranking process for the primary resource when the primary resource is represented as a search result responsive to a query.
In essence, Google can look at the user interaction from search of resources linked to from your page & determine if those pages tend to get a high CTR and tend to have a significant number of long clicks. If the pages you link to have great engagement metrics from search then Google can boost the ranking of your site. Whereas if the pages you link to have poor engagement metrics you could rank lower.
The prior user interactions with the respective secondary resource can represent an aggregation of multiple users' interactions with the secondary resource. The prior user interactions with the respective secondary resource can include a median access time or a click-through-rate associated with the respective secondary resource.
The same sort of engagement metrics referenced elsewhere (high CTR, long dwell time) are core to this.
User interaction data are derived from user interactions related to the resource and resources accessible through the resource, e.g., click through rates, user ratings, median access time, etc. In some implementations, a resource's click-through-rate for a given period of time is derived from the number of times users have been provided with an opportunity to access the resource and the number of times users have actually accessed the resource. A simplified example for calculating the click-through-rate of a resource presented P times and accessed A times (aggregated over multiple user sessions) is expressed as the ratio of A/P.
And Google could look at the pages linked to from the pages that are linked to, taking a view down multiple layers.
The one or more scores include, for example, a reachability score (RS) computed by the resource reachability system 120. Generally speaking, an RS is a score representing a number of resources a user is likely to visit by traversing links from the initial resource and/or an amount of time a user is likely to spend accessing a resource that is responsive to a query, including other resources linked (e.g., by hyperlinks or other associations) to the resource. The other resources are referred to as secondary or children resources. Secondary resources include grandchildren or tertiary resources, relative to the initial resource, great-grandchildren resources, etc. In general, each of the resources accessible by traversing links from the initial resource is referred to herein as a secondary resource unless otherwise specified.
If the sites & pages which are linked to are deemed to be trustworthy then that enhances the reachability score ranking boost.
In some implementations, the resource reachability system 120 is tuned to exclude certain secondary resources in calculating reachability scores for each primary resource. For example, a trustworthiness score T indicates whether the resource is reliable (i.e., includes relevant information) based on prior user interactions and optionally, a quality measure of the resource, based on intrinsic features. User interactions indicating trustworthiness include, for example, long clicks, source of resource, etc.
...
Only the resources with a T measure exceeding a corresponding threshold measure are selected for use in determining the RS of the primary resource.
One of the interesting aspects of this patent is that while it covers typical text documents and web videos, it primarily uses videos in the examples throughout. In spite of primarily using video as the example, they still include some of the same concepts they do with text documents in terms of long clicks, short clicks, and dwell time.
In some implementations, a long click of a video occurs if the video is viewed in excess of a playback duration that defines threshold view time, e.g., 30 seconds. In some implementations, if the video resource is a video of less than 30 seconds duration, then a long click occurs if the entire video is viewed at least once during a session. Alternatively, if the video resource is a video of less than 30 seconds duration, then a long click occurs if the entire video is viewed at least twice during a session. As used herein, the term “view” means that the video is played back on a user device without interruption, e.g., without navigating to another web page, or causing the browser window in which the video is being played back to become an inactive window. Other definitions can also be used.
What is particularly interesting about this patent is indeed Google *did* implement something like this on YouTube, on March 15th of 2012. They changed YouTube's recommendation and ranking algorithms to instead go after total view time rather than a raw number of video views. This in turn harmed some of the eHow-lite styled video content producers which showed a spammy image still or a 10 second sports highlight filled with nonsensical looping or irrelevant commentary. However the algorithm shift vastly increased overall view time per session (by about 300%) & in turn allowed Google to show more ads.
Going back to the patent, ...
Particular implementations of the subject matter described in this specification can be implemented to realize one or more of the following advantages. A resource's reachability score may provide an indication of the amount of time a querying user is likely to spend accessing the resource and any additional resources linked to the resource. Such a score may be used in a scoring function to produce search results that improve user experience and potentially improve an advertiser's ability to reach the user.
ADDED: After finishing the initial version of this document, Bill Slawski reviewed another approved Google patent on using video watch time as a ranking signal. It was filed on March 6th of 2013. For a patent on a business process invention to be valid it has to be filed within a year of when that process was first used in commerce. Here is the general concept:
In general, the system boosts the score for a search result if users historically tend to watch the resource for longer periods of time, and may demote the score if users historically tend to watch the resource for shorter periods of time.
They can compare the watch time of the top ranked search result as a baseline to judge other results by. If something gets watched longer then it can get a ranking boost. If something is either rarely selected by end users and/or has a short watch time when selected, then it can get ranked lower.
They also state this watch time concept could be applied to other media formats like web pages or listening to audio files, and they could count the chain of subsequent user actions as being associated with the first "viewing session" unless the session has ended (based on indications like going back to the search results and clicking on another listing, or searching again for a different keyword).
The performance data can be collected at a granular level on a query-document pair basis, and even granularized further from there based on language or user location. Individual users can also have their typical watch times modeled.
Usage data tends to have a self-reinforcing bias to it. Google can normalize the data on older videos when analyzing newer videos by weighting recent (CTR & watch time per view) data or only looking at performance data since the new video got its first impression ranking for that particular keyword.
Google offers publishers a watch time optimization guide here & ReelSEO offers a more detailed guide here.
High Value Traffic vs Highly Engaged Traffic
In many cases traffic value and engagement are roughly correlated: people who really want something will walk through walls to get it.
However, there are many markets where the streams are distinctly separate. For example, some people might want quick answers to a question or to know the background and history around a subject. They might be highly interested in the topic, but have limited commercial intent at the time.
In the travel vertical hotel bookings are the prime driver of online publishing profits. But if you focus your site on hotels, no matter how fantastic your editorial content is, it is almost impossible to build enough awareness and exposure to beat established market leaders if you are a rough complement to them. If you don't own traffic distribution you are screwed.
Booking online flights is a far lower margin piece of travel. And yet a site like Hipmunk which eventually planned to monetize hotels still started on flights because it was easier to have a scalable point of differentiation by focusing on the user experience and interface design.
Smaller publishers might focus on other forms of travel or history related content and then cross-sell the hotels. Over the years in the community Stever has shared all sorts of examples in the forums on building strategies around locations or events or historical aspects of different regions.
When there was almost no barrier to entry in SEO you could just immediately go after the most valuable keywords & then build out around it after the fact. Now it is more about building solid engagement metrics and awareness off of market edges & then pushing into the core as you gain the engagement and brand awareness needed to help subsidize the site's rankings on more competitive keywords.
I Just Want to Make Money. Period. Exclamation Point!
Affiliates were scrubbed. Then undifferentiated unbranded merchants were scrubbed. Over time more and more sites end up getting scrubbed from the ecosystem for a real or perceived lack of value add. And the scrubbing process is both manual and algorithmic. It is hard to gain awareness and become a habit if the only place you exist along the consumer funnel is at the end of the funnel.
If a person designs a site to target the high value late funnel commercial search queries without targeting other queries, they may not have built enough trust and exposure in the process to have great overall engagement metrics. If a person learns of you and knows about you through repeated low-risk engagements then the perceived risk of buying something is lower. What's more, ecommerce conversion rates tend to be fairly low, especially if the merchant is fairly new and unknown. And not only do many ecommerce startups carry ads, but even many of the largest ecommerce sites with the broadest selections and lowest prices (like Amazon or eBay or Walmart) carry ads on them to expand their profit margins.
By targeting some of the ancillary & less commercial terms where they can generate better engagement metrics, a store / publisher can build awareness and boost the quality of their aggregate engagement metrics. Then when it comes time for a person to convert and buy something, they are both more likely to get clicked on and more likely to complete the purchase process.
Competing head on with established players is expensive. Some newer networks like Jet.com are burning over $5 million per month to try to buy awareness and build network effects. And that is with clicking through their own affiliate links to try to save money. In many cases items they are selling at a discount are then purchased at retail prices on competing sites:
Jet’s prices for the same 12 items added up to $275.55, an average discount of about 11% from the prices Jet paid for those items on other retailers’ websites. Jet’s total cost, which also includes estimated shipping and taxes, was $518.46. As a result, Jet had an overall loss of $242.91 on the 12 items.
Panda & SEO Blogs
When the web was new, you could win just by existing. This was the big draw of the power of blogging a decade ago. But over time feed readers died, users shifted to consuming media via social sites & it became harder for a single person to create a site strong enough to be a habit.
Search Engine Roundtable publishes thousands of blog posts a year & yet Barry was hit by the Panda algorithm. Why was his site hit?
- Many posts are quick blurbs & recaps rather than in-depth editorial features which become destinations unto themselves
- If you are aware of Barry's site and visit it regularly then you may know him and trust him, but if you are a random search user who hasn't visited his site before, then if you land on one of the short posts it might leave you wanting more & seeking further context & answers elsewhere. That could lead to a short click & heading back to Google to conduct another background research query.
- The broader SEO industry is going through massive carnage. Old hands are quitting the game, while newer people entering the field are less aware of the histories of some well established sites. Many people newer to the field who know less of its history prefer to consume beautifully formatted and over-simplified messaging rather than keeping up with all the changes on a regular basis.
- Another big issue is Barry almost turns some of his work into duplicate content (in terms of end user habits, rather than textual repetition). And by that I mean that since he works with Search Engine Land, much of his best work gets syndicated over there. That in turn means many of the better engagement-related metrics his work accrues end up accruing to a different website. Further, SEL offers a daily newsletter, so many people who would regularly follow SERoundtable instead subscribe to that SEL newsletter & only dip in and out of SER.
If SER was hit, why wasn't SEObook also hit? I don't blog very often anymore & much of our best content remains hidden behind a paywall. I don't go to the conferences or work hard to keep my name out there anymore. So in theory our site should perhaps get hit too if SER got hit. I think the primary reason we didn't get hit is we offer a number of interactive tools on our site like our keyword density tool and our keyword research tool. Some people come back and use these repeatedly, and these in turn bleed into our aggregate engagement metrics. We also try to skew longer & more in-depth with our editorial posts to further differentiate our work from the rest of the market. We are also far more likely to question Google spin and propaganda than to syndicate it unquestioned.
It sounds like after 10 months of being penalized SER is starting to recover, but if Google is false positive torching sites with 10,000 hours of labor put into them, then so many people are getting nailed. And many businesses which are hit for nearly a year will die, especially if they were debt leveraged.
Engagement as the New Link Building
A lot more people are discussing brand engagement. Here's a recent post from Eric Enge, an audio interview of Martinibuster, and a Jim Boykin YouTube video on brand awareness and search engagement related metrics.
Guys like Martinibuster and Jim Boykin went out of their way to associate themselves with links. And now they are talking engagement.
And people like Nick Garner have mentioned seeing far more newer sites rank well without building large link profiles.
How Engagement is Not Like Links
If you create a piece of link bait which is well received the links are built & then they stick. No matter what else you do, many of those links stick for years to come.
User engagement is an ongoing process. It isn't something which can easily be bolted on overnight in a one-time event. If a site stops publishing content its engagement metrics will likely fall off quickly.
And things which are easy to bolt on will be quickly bolted onto by search engines themselves to keep people within the search ecosystem. Here's a quote from Baidu's CEO Robin Lee:
Do you see yourself more as an e-commerce company than a search company?
It’s very hard to differentiate those two. Search was the facilitator for commerce. But in the mobile age, we have to do a closed-loop action, not just a query. So, it’s more of a combination now.
It is easy to use the advice "create engaging content" but in reality sometimes the engagement has to come from the core of the business model rather than being something which is bolted onto a site in a corner by a third party marketer. Many consumer benefits (price, speed, variety) apply across markets. But some of them are specific to knowing your market well and knowing what people really care about. This applies to search as much as any other market. See Google's focus on speed & mobile, or this story on the fall of Lycos:
In our ongoing efforts to make search results better, Dennis set up an eye-tracking lab and began scientific testing of how people used search. We watched where people looked on the pages and noticed something shocking: people didn’t look at the ads. Not only that, but the more we tried to make the ads stand out, the less people looked at them. Our entire advertising philosophy was based on making ads flashy so people would notice them. But we saw, quite counterintuitively, that people instinctively knew that the good stuff was on the boring part of the page, and that they ignored the parts of the page that we—and the advertisers—wanted them to click on.
This discovery would give us an edge over everyone in the industry. All we had to do was make the ads look less like ads and more like text. But that was not what the ad people wanted, and the ad people ran Lycos.
There are even some sorts of sites where people *expect* there to be a bit of a delay & a "working" message, and trust a site less if the results are shown too quick. But such outliers are hard to know in advance & are hard to predict unless you know the market and the psychology of the user. Each market is every bit as unique & absurd as the following terrible logo.

The problem with creating an engaging site is it is quite hard to just bolt it on. To offer an interactive service which compels people to repeatedly use it you typically need to know the market well, need to know pain points, need to know points of friction, need a good idea of where the market is headed, need to have programmers (and perhaps designers) on staff, and you need to keep investing in creating content and marketing it.
If you have passion for a market it is easy to have empathy for people in the market and it is easy to predict many types of changes which will happen in the market. If you don't have passion for a market and want to compete in a saturated market then there is a lot of pain ahead.

Like it or not, the chunk size of competition is increasing:
Closed platforms increase the chunk size of competition & increase the cost of market entry, so people who have good ideas, it is a lot more expensive for their productivity to be monetized. They also don't like standardization ... it looks like rent seeking behaviors on top of friction
One of my favorite sites in terms of highlighting how a small team can create a bottoms up marketplace through knowing the market better than others and incrementally investing in the product quality is the collectible website Check Out My Cards / COMC.com. Off the start when they were newer they had to charge a bit more for shipping, but as they became larger they kept lowering costs and adding features. Some of their compelling benefits include...
- meticulous & correct product labeling, with multiple versions of the card side-by-side (which encourages vendors to lower prices to get the sale)
- centralized inventory and payment processing (which reduces the need for seller and buyer reputation scoring)
- fantastic site search & sorting options (by date, price, player, set, print run, popularity, team, percent off, recently added to the site, etc.)
- high resolution images of items (this allows sellers to justify charging different prices for the same inventory, allows buyers to see what copies are in the best shape and might be worth grading, and allows the site to create embeddable widgets which can be embedded in other sites linking back to the source)
- flat price listings along with the ability to negotiate on pricing
- standardized bulk low-cost shipping
- the ability to drop off cards for inclusion in the marketplace at large card shows
- the ability for buyers to leave things stored in the warehouse until they want them shipped, or being able to relist them for sale (which allows people to track hot players and changes in market demand to buy up inventory and hold it for a bit as the price goes up)
- they licensed card price data from Beckett for years & then created custom pricing catalog information based on prior sales throughout the history of the site
- etc.
When I looked up COMC on SimilarWeb only 19.52% of their overall traffic came from the search channel. The other 80% of their traffic gets to leave trails, traces & clues of user trust - relevancy signals which bleed over into helping search engines boost their organic search rankings.
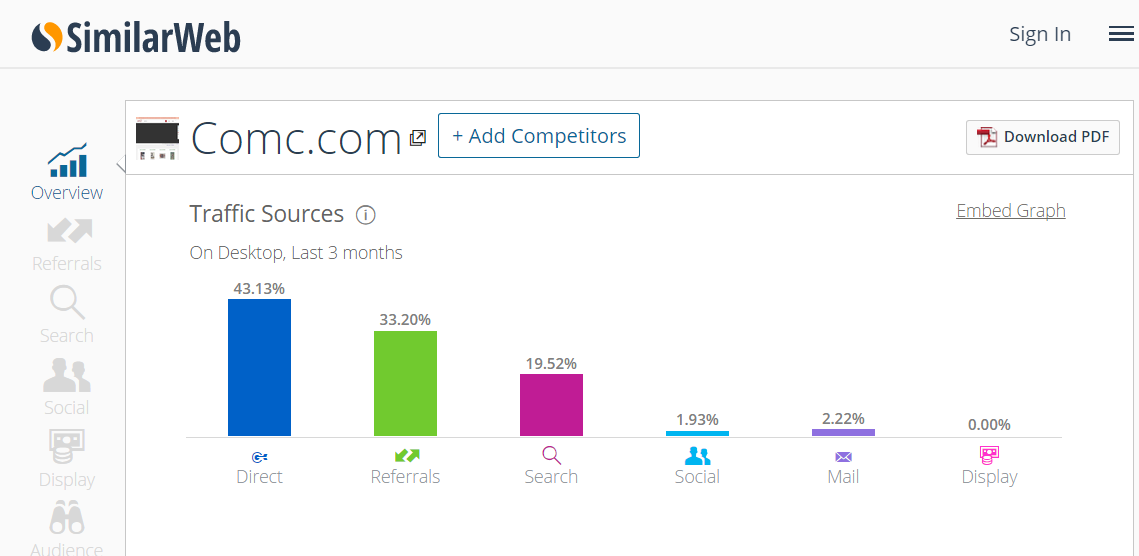
And, as good as those hundreds of thousands of monthly regular direct users are, even much of the "search" traffic for the site is brand-related reference queries.
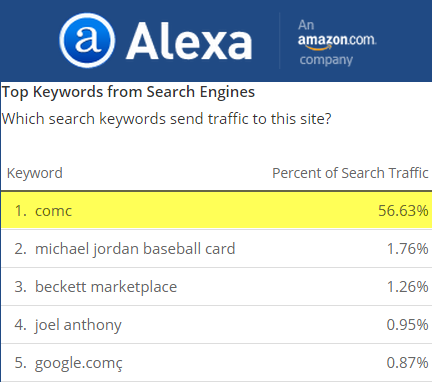
If most of your traffic is direct or via your own brand term that limits the downside impact Google can have on your business. To hurt you and not rank you for your branded keyword terms they have to hurt themselves. COMC only has a few hundred unique linking domains, but if they ever seriously approached link building with featured editorials based on stats from their marketplace and the sports they follow, they would have amazing SEO success.
Another collectible site I like is Price Charting. It focuses on video game prices. The have great sorting features, historical pricing charts, downloadable buying guides, custom game images which can be purchased in bulk and downloaded, a deal hunter tool which allows you to track eBay for new listings or auctions near their close where items are well below their normal retail price, and a blog covering things like rare games for sale and how to tell real games from fakes, etc.
The bigger sites like Amazon and eBay have lots of network effects behind them. And then Amazon is known for buying vertical sites to increase their share in the vertical (Audible.com, Zappos, etc.), drive informational searchers toward commerce (IMDB), or differentiate the Amazon.com buying experience (DPReview).
When you compete against Amazon or eBay you are not only competing against their accumulated merchant and product reviews, but also the third party ecosystem around them including their broad array of affiliates and other third party tools built around their data & service like Price Charting or bid snipers like Gixen or JBidWatcher. If you focus exclusively on the commercial keywords & want to launch a horizontal marketplace it is hard to have a compelling point of differentiation.
But if you go to a market edge or focus on a small niche (say a service like Buyee offering international shipping on Yahoo! Japan auctions) you can differentiate enough to become a habit within that market.
COMC stands for "check out my collectibles." Originally it stood for "check out my cards" which was the original domain name (CheckOutMyCards.com) before it was shortened to COMC.com. They planned on expanding the site from cards to include comics and other collectibles. But when Beckett terminated licensing their pricing catalog, COMC retrenched and focused on improving the user experience on sports cards. They have continued to add inventory and features, taking share away from eBay in the category. They've even tested adding auctions to the site.
Change the Business Model
The reason COMC is able to keep taking share away from eBay in the baseball card market is they remove a lot of friction from the model. You don't pay separate shipping fees for each item. You don't have to wait right until an auction is about to end. You don't have to try to estimate condition off of lower resolution pictures. Other businesses in the past couldn't compete because they had to carry the inventory costs. As a marketplace there is limited inventory cost & much of those costs are passed onto the sellers.
The other big theme played out over and over again is taking something which is paid (and perhaps an intensive manual process) and finding a way to make it free, then monetize the attention streams in parallel markets. Zillow did this with their Zestimates & did it again by offering free access to foreclosure and pre-foreclosure listings.
TV commercials for years informed consumers of the importance of credit reports and credit scores. Then sites use the term "free" in their domain names, when really it was perhaps a free trial tied to a negative billing option. Then Credit Karma licensed credit score data & made it free, giving them a valuation of $3.5 billion (which is about 10X the value of Quinstreet and 3X the value of BankRate).
Plenty of Fish was a minimalistic site which entered a saturated market late, but through clever marketing and shifting the paid business model to free the market leader had to pay Markus Frind over a half-billion dollars for the site in a defensive purchase.
Put Engagement Front and Center
In some cases an internal section of a site takes off and becomes more important than the original site. When that happens it can make sense to either shift that section of the site to the site's homepage, over-represent that section of the site on the homepage, or even spin that section out into its own site. For example, our current site had a blog on the homepage for many years. That blog was originally an internal page on a different website, and I could see the blog was eclipsing the other site, so I created this site while putting the blog front and center.
When you own a core position you can then move the site into the ancillary and more commercial segments of the market. For example, Yahoo! Sports is a leader in sports, which allowed them to then move into Fantasy Sports & eventually into paid Fantasy Sports. And when launching new sections within their verticals, Yahoo! can get over the chicken-vs-egg problem by selling ad inventor to themselves. Look at how many Yahoo! Fantasy sports ads are on this page.
For just about anyone other than ESPN, it would be hard to try to create a Yahoo! Sports from scratch today. ESPN's parent Disney intended to invest in a fantasy sports gambling site, but backed away from the deal over image concerns. The two biggest pure plays in fantasy sports are Draft Kings & Fan Dual, with each recently raising hundreds of millions of dollars. A majority equity stake in the #3 player DraftDay was recently sold for $4 million.
The sort of strategy of putting something engaging front and center can apply to far more established & saturated markets. And that in turn can act as an end around entry into other more lucrative markets. If Draft Kings and Fan Dual each have valuations above a billion dollars (and they do) and the #3 player is valued (relatively) at about the price of a set of steak knives, what's another approach to entering that market?
One good approach would be creating a stats site which has many great ways to slice and dice the data, like Baseball-Reference.com or Fan Graphs. Those stats sites get great engagement metrics and avail themselves to many links which a site about gambling would struggle to get.
Some of the data sources license paid data to many other sites & some provide data free. So if many people are using the same source data, then winning is mostly down to custom formatting options or creating custom statistics from the basic statistic packages & allowing other sites to create custom embeds from your data.
The cost of entry for another site is quite low, which is why players like FindTheBest have created sites in the vertical. Notice PointAfter is growing quickly, and this is after FindTheBest itself cratered.
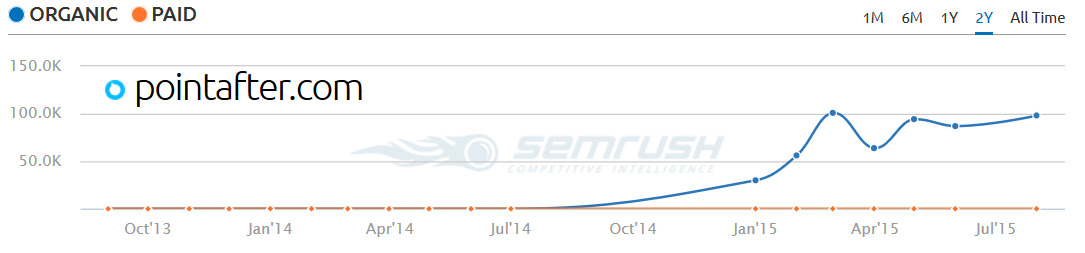
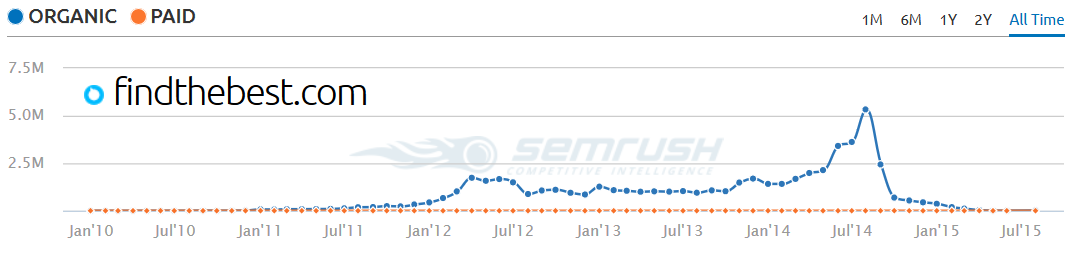
That's because the sports stats are more interesting and engaging to sports fans than the random (and often incorrect! set of "facts" offered on the overly broad FindTheBest site). The same formula which failed on FindTheBest (aggressive link building, data embeds, scraped duplicate content, auto-generated QnA pages, etc.) can succeed on PointAfter because people are passionate about sports.
I probably wouldn't recommend being as aggressive as FTB is with auto-generating QnA pages and the like (unless one is funded by Google or has other important Google connection), but the efficacy of a formula depends as much on the market vertical as the underlying formula.
As the stats sites get more established, they could both add affiliate links for fantasy sports sites (likeso), and they could add their own "picks" sections or custom player valuation metrics. Eventually they could add news sections & if they had enough scale they could decide to run their own fantasy sports gaming sections.
Section Recap
- As painful as SEO may currently be, SEO for marketers focused exclusively on the SEO vertical is only going to keep growing more painful.
- If you can't become the news site for a vertical, it probably makes sense to publish with less frequency and greater depth.
- Some engagement issues can be fixed by improving a site's design, or by removing ads from key pages. In many cases fixing engagement issues is much harder though, requiring a remake of the core underlying business model.
- If you are struggling to build rank & struggling to build links, it can make sense to try to build aspects of your site around things people will find compelling and engaging, and then later add the commercial pieces in.
Questions to Ask Yourself
- If engagement is in part a function of trust & awareness, what channels other than organic search (e.g. display ads, social sites, retargeting, offline marketing, selling on other trusted sites, etc.) are you leveraging to catch up to established organic search leaders?
- How can you remove pain or friction from the buying cycle through established leaders? Is there a way you can turn this pain into an enemy & a remarkable marketing angle (like HipMunk did with flight layovers and the like)?
- In what way could you alter your business model that established competitors can't copy without drastically harming their current revenue streams?
- For pages which monetize poorly but get great engagement metrics, have you considered removing all monetization in order to further improve the engagement metrics?
- How engaging is your site compared to established competing sites? Use competitive research tools like SimilarWeb, Compete.com and Alexa to look at things like: the ratio of visits to unique visitors, pageviews per visitor, time on site, and bounce rate.
- If you struggle to create strong enough engagement metrics to compete with larger sites, does it make sense to list your products or business on trusted platforms like Yelp, TripAdvisor, Amazon.com & Etsy and then try to rank those pages? In some cases you can encourage reviews by including requests within packages or sending people automated emails after delivery. And you can further increase your exposure on those types of platforms by buying ads promoting your listings on those sites, link building for your pages on those sites, or having a few friends buy your products and leave positive reviews.
Up Next: Summary: this is a recap of the article and exits the series with a motivational quote.

