

Focus On the User: Leveraging Usage Data in Search Relevancy Algorithms

Sections
- TL;DR
- Classic Information Retrieval
- Links = SEO
- Filtering Signals vs Throwing Away Data
- Augmenting Link Data With Click Data
- Activity Bias
- Domain Bias
- Navigational Searches
- Panda
- General Usage Data Usage
- Filtering Out Fake Users & Fake Usage Data
- Localizing Search Results
- Historical Data
- Engagement Bait
- Best Time Ever
- The Beatings Shall Go On...
- Rank Modifying Spammers
- Gray Areas & Market Edges
- Facts & Figures
- No Site is an Island
- High Value Traffic vs Highly Engaged Traffic
- I Just Want to Make Money. Period. Exclamation Point!
- Panda & SEO Blogs
- Engagement as the New Link Building
- How Engagement is Not Like Links
- Change the Business Model
- Put Engagement Front and Center
- In Closing
TL;DR
The following article was intended to be something like 20 or 30 pages, but as I kept reading more patents I kept seeing how one would tie into the next and I sort of just kept on reading, marking them up, quoting them, and writing more. The big takeaway is that much of Google's modern algorithm is driven by engagement metrics. It might not have outright replaced links (& links can still be used for many functions like result canonicalization and generating the initial seed result set), but engagement metrics are fairly significant. To break it down into a few bullet points, Google can...
- compare branded/navigational search queries to the size of a site's link profile to boost rankings for sites which users seek out frequently & demote highly linked sites which few people actively look for
- compare branded/navigational search queries to the size of a site's overall search traffic footprint to boost rankings for sites which users seek out frequently & demote sites which few people actively look for
- normalize anticipated CTR on a per-keyword level & track how a site responds to auditioned ranking improvements, and if people still actively seek out & click on the result if it is pushed a bit further down the page
- boost rankings of sites which people actively click on at above normal rates
- further boost user selection data from within the SERPs by counting "long clicks" (click with a high "dwell time" - where a user clicks on them then doesn't return to the SERPs shortly after)
- demote sites & pages where people frequently click back to the SERPs shortly after clicking on them (by comparing the ratio of "long clicks" to "short clicks")
- use Chrome and Android usage data to track usage data for sites outside of the impact of SERP clicks
- use their regional TLDs and registered user location data to further granularize and localize their data
- have many traps built into their algorithms which harm people who focus heavily on links without putting much emphasis on engagement
The following is a review of many of Google's patents related to engagement metrics. Not all these patents may be used by Google in their ranking algorithms today, but Google tests making well over 10,000 relevancy changes a year & the 500 or 1,000 or so with desirable outcomes end up getting implemented.
Each year computing gets faster, more powerful, and cheaper. That in turn enables Google to do more advanced computations and fold more signals into their relevancy algorithms. One of Google's key innovations with their data centers is using modular low-cost hardware. But as computing keeps getting cheaper they could eventually implement in real time some algorithmic aspects they compute offline. Just like solid state drives are faster than traditional hard drives, next year Intel and Micron are expected to start selling 3D XPoint memory, which is up to 1,000 times faster than Nand flash storage in memory cards & SSDs.
Every day Google has more computing horsepower and more user data at their disposal. Things which are too computationally expensive today may eventually end up being cheap.
Classic Information Retrieval
Shortly after Amit Singhal joined Google, he rewrote some of Google's core relevancy algorithms. When he studied information retrieval he studied under Gerard Salton, whose A Theory of Indexing is a great introduction to on-page information retrieval relevancy factors. It highlights classical IR concepts like term frequency, inverse document frequency, discrimination value, etc.
The sort of IR described in that book (published in 1987) works great when there is not an adversarial role between the creator of the content within the search index and the creator of the search relevancy algorithms. However, with commercial search engines, there is an adversarial relationship. Many authors are unknown and/or are driven by competing business interests and commercial incentives. And the search engine itself has incentives to try to push as much traffic as possible through their ad system & depreciate the role of the organic search results. In some of Google's early research they concluded:
Currently, the predominant business model for commercial search engines is advertising. The goals of the advertising business model do not always correspond to providing quality search to users. For example, in our prototype search engine one of the top results for cellular phone is "The Effect of Cellular Phone Use Upon Driver Attention", a study which explains in great detail the distractions and risk associated with conversing on a cell phone while driving. This search result came up first because of its high importance as judged by the PageRank algorithm, an approximation of citation importance on the web [Page, 98]. It is clear that a search engine which was taking money for showing cellular phone ads would have difficulty justifying the page that our system returned to its paying advertisers. For this type of reason and historical experience with other media [Bagdikian 83], we expect that advertising funded search engines will be inherently biased towards the advertisers and away from the needs of the consumers.
As a sidebar, my old roommate in college ran research experiments where he mutated switchgrass using radio waves. He suggested if you could mutate switchgrass then the same types of radio waves could indeed cause cancer, but there is no source of funding for that type of research. And if there were, it would be heavily fought by Google given much of their growth in ad revenue has came from mobile ad clicks. And, as absurd as that sidebar is, it is also worth noting Google has fought against proposed distracted driving laws!
Google Inc has deployed lobbyists to persuade elected officials in Illinois, Delaware and Missouri that it is not necessary to restrict use of Google Glass behind the wheel, according to state lobbying disclosure records and interviews conducted by Reuters.
While Google hasn't become an across-the-board shill for all big businesses, they have certainly biased their "relevancy" algorithms toward things associated with brand.
Here is a look at a current search results for [cell phones].
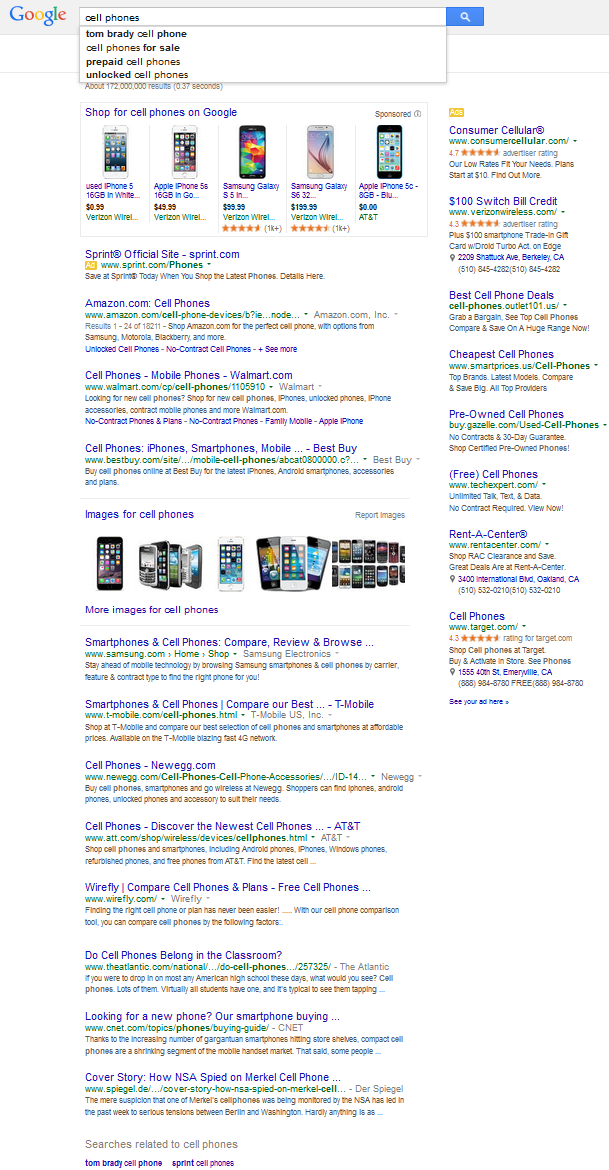
Note that almost every entity listing on that page is either a billion dollar company, is paying Google for an advertisement, or both. There are a few token "in-depth articles" at the bottom of the search result page, but few people will see them.
Links = SEO
PageRank
When Google was founded PageRank was a key differentiator between them and prior search services which weighed on-page factors more. I got into SEO back in 2003 & back then all you needed to rank for just about anything was a handful of keyword-rich inbound links. You could rank well in multi-billion Dollar industries within a month or two on a few thousand dollars of investment, so long as that investment went into links. TripAdvisor, which was set up as an example site to highlight the underlying features they desired to sell to other travel sites, quickly grew to a multi-billion dollar valuation on the back of paid links driven SEO success.
Back in August of 2006 I co-authored an article about link building listing many ideas (an article which is woefully outdated in the current marketplace, given Google has suggested one shouldn't even dare ask for links (though they later walked back that restraint of trade), Google now feels disavow justifies forcing people to spend on cleaning up unsolicited spam links from third parties, Google has stated they have a goal of breaking people's spirits & Google has an absurd 2-tier approach to selective enforcement where their investments are rarely penalized & if penalized it is only for a short duration).
The Death of Links = SEO
Early on in the article about link building, we quoted Brett Tabke's Robots.txt blog:
What happens to all those Wavers that think Getting Links = SEO when that majority of the Google algo is devalued in various ways? Wavers built their fortunes on "links=seo". When that goes away, the Wavers have zero to hold on to.
I think the last featured article I published in the member's area here was titled links and the glass ceiling. It tried to echo the problem with a links only view of SEO. That article wasn't published until February of 2013, so links = SEO still had a good 6 or 7 year run from when Brett Tabke warned of the mindset. ;)
Or, at the very earliest, the death of links = SEO would be February of 2011 when the Panda update rolled out. But that impacted some sites more than others & some sites managed to fly below radar for a year or two. Some smaller categories remain less impacted by Panda to this day.
In some verticals like local there might be other signals like local citations which augment links, but links are still powerful & the backbone of SEO. If they were not, we would no see so much propaganda about them. There would not have been the Penguin update, warnings against asking for links, nor all the manual link penalties. In markets with limited usage data for Google to rely on, links = SEO is still as true as it was back in 2006. Certainly Google has grown more selective and tightened down various filters, but tiny markets are tiny markets & thus have limited usage data to augment links.
Filtering Signals vs Throwing Away Data
Over the years the idea of using search CTR data to refine search relevancy scoring has been debated at great length. Typically when Matt Cutts has mentioned the topic he sort of dismisses the idea (or misdirects attention) by claiming "the data is noisy." But that Google knows the data is so noisy would indicate they've at least tested using the data. A data source being noisy doesn't mean the source must be discarded, but rather that one would need to massage away some of the noise in order to use it.
"It can be a great tool, but it's also easily manipulated. That being the case, if it were my engine, I would go out of my way to convince my enemy I would never user it. That way I could use it without the data being tainted." - Greg Boser
Google has done the same sorts of refinements with link data. They penalize overly aggressive anchor text, they try to count local links more, etc.
"in Austria, where they speak German, they were getting many more German results because the German Web is bigger, the German linkage is bigger. Or in the U.K., they were getting American results, or in India or New Zealand. So we built a team around it and we have made great strides in localization. And we have had a lot of success internationally." - Amit Singhal
That sort of filtering process on usage data has certainly been considered, given Matt Cutts has stated on algorithmic relevancy updates: "we got less spam and so it looks like people don't like the new algorithms as much."
Augmenting Link Data With Click Data
Estimating vs Direct Tracking
Google's early efforts to fold usage data into the link graph were more around re-modeling PageRank based on presumptions and likelihoods of user behavior with links rather than directly observing user behavior. For example, a 2004 patent by Jeff Dean named Ranking documents based on user behavior and/or feature data isn't really discussing using usage data from the search engine itself, but rather modeling which links are more likely or less likely to be clicked by a user reading a particular web page.
A larger font size and a link above the fold pointing into a document on a related topic in the main content area of the page is more likely to be clicked. A link in the footer to the terms of service, a link which is below the fold, a link near the bottom of a list of links, a link to an irrelevant page, or a link to a parked domain, etc. ... is less likely to get clicked.
So in spite of the above patent name, this patent was more about further adjusting the links on the link graph to estimate the probability of user behavior on that page (is a user likely to click on this link or not), rather than creating a complimentary or competing relevancy signal which could replace the importance of links.
By using signals other than links Google ensures that many players who buy a store of links (through recycling a well-linked expired domain or such) struggle to rank on a sustainable basis. If they go for big money keywords and do not have great engagement metrics then they still might get clipped by the usage data folding, even if they are missed by the remote quality raters, the search engineers, and the other algorithmic aspects.
Chrome & Android
It wasn't until Google had a broad install base for Chrome and Android that they started putting serious weight on how users interact with the results. In fact, for many searches for many years the links in the search results were coded as direct links rather than tracking URLs. The Chrome web browser launched in September of 2008 & by February of 2011 the Panda algorithm was live.
And Google isn't the only company tracking users across devices for ad targeting & attribution. Facebook has leveraged their user profiles as logins for other apps & the new Windows 10 launch is largely about cross-device user tracking for ad targeting.
Clickstream Data
One of the better publicly published blog posts in the last 5 years about SEO was the recent post by A.J. Kohn asking Is Click Through Rate a Ranking Signal? In the article he cites a couple patents and the following Tweet, which quotes Udi Manber on using click distributions to adjust rankings: "The ranking itself is affected by the click data. If we discover that, for a particular query, hypothetically, 80% of people click on Result No. 2 and only 10% click on Result No. 1, after a while we figure it out, well probably Result 2 is the one people want. So we'll switch it."
Google confirms watching clicks to evaluate results quality. FYI Google still won't say if clicks used as rank signal pic.twitter.com/jzNGc5reQk— Danny Sullivan (@dannysullivan) March 25, 2015
The Udi Manber quote came from the leaked FTC Google review document.
Bing has also admitted to using clickstream data. They not only used clickstream data from their own search engine, but Google conducted a sting operation on Bing to show Bing was leveraging clickstream data from Google search results. This is perhaps one of the reasons Google shifted to using HTTPS by default: to block competitors from being able to leverage their search data to modify user experience. While the FTC document highlighted how Google scraped Amazon sales rank data for products, an article in TheInformation later stated people like Urs Holzle "felt irked" when Google search query stream data leaked to competitors like Amazon.
Dozens of Patents, Tons of Data
If Google has a stray patent here or there about potentially using a signal, then perhaps they are not using it. But if Google has created about a dozen related patents & is blocking competitors from using the signals, there is a strong chance they are using the associated signals.
And while Google throws away the data of marketers to increase the cost and friction of marketing...
keywords don't matter, which is why Google and now Bing go to great lengths to hide them from SEOs. hint...hint.— john andrews (@searchsleuth998) June 30, 2015
... they are a pack rat with data themselves:
“It’s not about storage, it’s about what you’ll do with analytics,” said Tom Kershaw, director of product management for the Google Cloud Platform. “Never delete anything, always use data – it’s what Google does.” “Real-time intelligence is only as good as the data you can put against it,” he said. “Think how different Google would be if we couldn’t see all of the analytics around Mother’s Day for the last 15 years.”
If Google is valuing the older usage data, then that doesn't mean they're ignoring it.
Rather they are storing it and using it as a baseline to evaluate new data against. They can track historical data & use it to model the legitimacy of new content, new content sources, new usage data, new user accounts providing usage data, etc.
Activity Bias
What is Activity Bias?
There is a concept called activity bias, where by actively targeting people you end up targeting people who were more pre-disposed to taking a particular action. The net effect is correlated activities may be (mis)attributed as causal effects.
At the same time advertisers are trying to target relevant consumers to increase yield, ad networks also automatically use campaign feedback information to further drive targeting:
If only males are clicking on the ad that promote high-paying jobs, the algorithm will learn to only show those ads to males. Machine learning algorithms produce very opaque models that are very hard for humans to understand. It’s extremely difficult to determine exactly why something is being shown.
Yahoo! published a research paper on this concept named Here, There and Everywhere: Correlated Online Behaviors Can Lead to Overestimates of the Effects of Advertising. eBay later followed up with a study named Consumer Heterogeneity and Paid Search Effectiveness: A Large Scale Field Experiment.
Monetizing Activity Bias With Ad Retargeting
There is a popular concept in online marketing called remarketing/retargeting, where companies can, for example, target potential customers who put an item in an online shopping cart but didn't complete their order. Some of these ads might contain the product which was in the cart and a coupon as a call to action. For smaller websites without well known brands, using retargeting is a way to build awareness and help push people over the last little hurdle toward conversion. For larger sites like eBay many people who convert would have converted anyway (activity bias) so an optimal approach for them would be to lower ad bids on ads for people who frequently visit their site and/or have recently visited their site; while increasing bids for people who either haven't visited their site or haven't visited it in a long time.
Google was quick to counter eBay's research in a paper of their own named Impact of Ranking of Organic Search Results on the Incrementality of Search Ads, which claimed paid search exposure was highly incremental.
Arbitraging Brand Equity
There are some people in online marketing who paint all affiliates as scum, while viewing any/all search ad spend as worthwhile. Some affiliates add value while others arbitrage the pre-existing consumer path without adding any value. The same is sometimes true with some search ad set ups. The distinctions between traffic channels get more blurry when one is participating in a rigged auction and bidding against themselves & the auction house keeps rolling out a variety of directly competing vertical services which they grant preferential placement to. It is also worth mentioning that Google Analytic's default set up with last click attribution favors the search channel & other late-stage demand fulfillment channels over early-stage demand creation channels.
Some paid search advertising set ups have advertisers arbitraging their own brand without attempting to justify the incremental impact of the clicks. If the click prices are cheap enough (and they are often priced low enough to be a no brainer) then perhaps blocking out competition and controlling the messaging has enough value to justify the cost, but there are cases where Google has drastically increased advertiser bids when they added sitelinks, or Google has tried to push the branded search traffic through Google Shopping to charge higher rates while arbitraging the brand traffic.
Smart paid search management segments branded versus unbranded search queries, such that they can be tracked and managed separately. The reason sloppy campaigns blend things together is because some service providers charge a percent of spend, and if they can used perceived "profits" from arbitraging the customer's brand to justify bidding higher on other keywords then the higher aggregate spend means higher management fees for less work.
Cumulative Advantage
In line with the concept of activity bias, there is another concept called cumulative advantage. People often tend to like things more if they know those things are liked by others. Back in 2007 the New York Times published an article on this featuring Justin Timberlake.
The common-sense view, however, makes a big assumption: that when people make decisions about what they like, they do so independently of one another. But people almost never make decisions independently — in part because the world abounds with so many choices that we have little hope of ever finding what we want on our own; in part because we are never really sure what we want anyway; and in part because what we often want is not so much to experience the “best” of everything as it is to experience the same things as other people and thereby also experience the benefits of sharing.
When Wikipedia editors try to slag the notability of someone, a popular angle is a quote like this one: "The subject's 'notability' appears to be a Kardashianesque self-creation."
What is left unsaid in the above quote is that Wikipedia publishes a 5,000+ word profile of Kim Kardashian.
Once you are established, brand awareness can help carry you. But when you are new you have to do whatever you can for exposure. For Kim, that meant a "leaked" sex tape with a rapper. For other people it might mean begging or groveling for exposure, putting some of your best work on someone else's site to get your name out there, pushing to create some arbitrary controversies, going to absurd length in covering a topic, spending tons of time formatting artistic work, or buying ads which barely break even.
In isolation, the story John Andrews highlighted in the following Tweet sounds like a quite limited success story.
“@ellisshuman: How I Sold 910 Copies of My Book in One Week
http://t.co/EHKn6yZMz0 NOTE: He made less than $200 profit.— john andrews (@searchsleuth998) July 6, 2015
However, if you consider activity bias, any exposure the author gets by the ad network for the testimonial, any exposure the author gets from other authors who want to live the dream, etc. ... then maybe the ROI on the above isn't so bad.
Once an artist or author is well known, then they have sustained instant demand for anything they do. Once they are mired in obscurity there is no demand for their work no matter how good it is.
Many marketplaces which sell below cost to get the word out end up going under. Most start ups fail. But if your costs are low & you are just starting out & are not well known, then anything which approaches break even while getting your name out there might be a win.
Domain Bias
Brands vs Generics
Bringing things back to the search market, domain names & branding are highly important. One of my old business partners is an absolutely brilliant marketer who worked for some of the big ad agencies and one of the points he made to me long ago was that when markets are new and barriers to entry are low one can easily win by being generically descriptive. Simply being relevant is enough, because relevancy creates affinity when there are few options to select from. Call this the "good enough" scenario. But as competition in markets heats up one needs to build brand equity to differentiate their offering and have sustainable profit margins.
There are a couple dimensions worth mentioning in how this applies to search.
- If a market is "new" there might not be enough scale to justify aggressive brand related marketing, thus one can succeed by entering the market early with a generic name & regular content creation. It is much harder to enter
- In some smaller local markets where there is less usage data (say Pizza shops in Ottawa, IL; or a niche in geographic markets where advertising is less prevalent than in the US) one can still win with a generic name. You can rank locally for Pizza, but it is hard to beat a big brand pizza chain like Dominos in ranking broadly across the country.
- When the search relevancy algorithms & Google's data hoard & computational power were more limited, more weight was placed on domain names which matched keywords. But as Google added other relevancy signals & verticalized search, those additional signals and channels lowered the value of generic domain names.
Brand & Profit Margins
To appreciate how hard it is to have sustainable profit margins without a strong brand, consider how some of the Chinese manufacturers improved their profit margins during the 2015 Chinese stock bubble:
“According to the latest official data, profits earned by Chinese manufacturers rose 2.6% from a year earlier in April, a turnaround from a drop of 0.4% in the previous month. Yet nearly all of that increase—97%—came from securities investment income, data from the National Bureau of Statistics show. Excluding the investment income, China’s industrial profits were up 0.09%. ... "Manufacturing is a very hard business these days,” said Mr. Dong, chairman of the company. “I want to make some money from the stock market and use the profits to restart my manufacturing business later, when the economy turns for the better.”
Manufacturers which couldn't turn a profit instead used their cashflow to gamble in the stock market. Those gains then get reported as earnings growth for the underlying companies. And some of the companies were pledging their own stock as collateral to gamble on the stock market.
An Introduction to Domain Bias
Microsoft put out a research paper titled Domain Bias in Web Search. In that paper they noted users had a propensity to select results from domain names of brands they were already aware of. The bias they are speaking of is more toward sites like Yahoo.com or WebMD.com than a generic name like OnlineAuctions.com or WebPortal.com.
Viewing content on the Internet as products, domains have emerged as brands.
Their study found that the domain name itself could flip a user's preference for what they viewed as more relevant about 25% of the time.
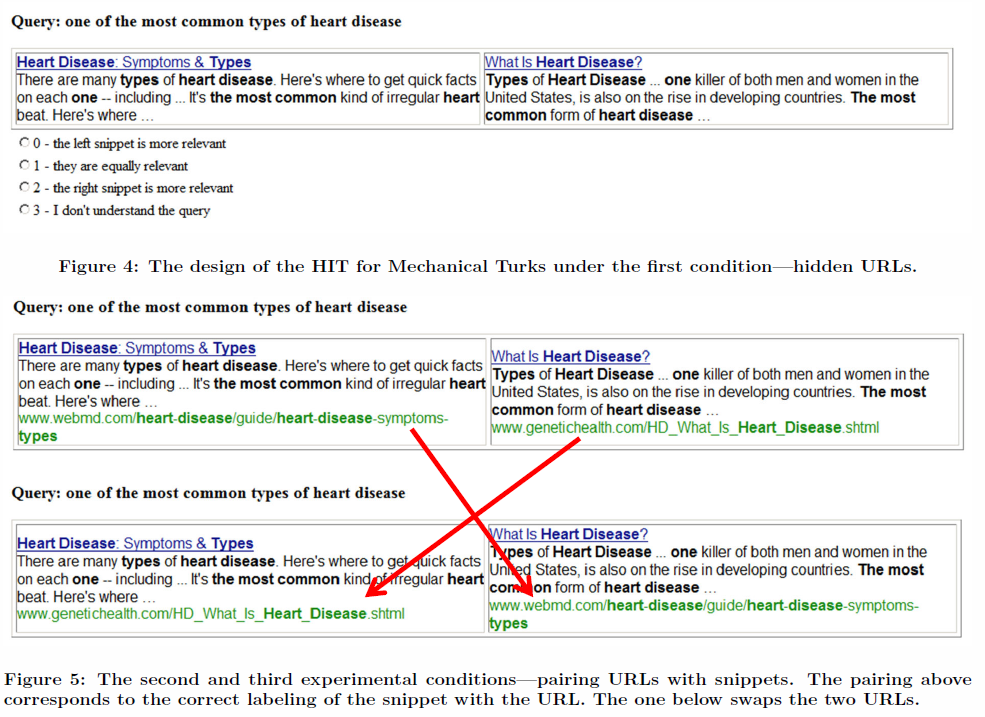
This feedback from users not only drives higher traffic (and thus revenues) to the associated branded sites, but it also creates relevancy signals which fold back into the rankings for subsequent searchers
the click logs have been proposed as a substitute for human judgements. Clicks are a relatively free, implicit source of user feedback. Finding the right way to exploit clicks is crucial to designing an improved search engine.
The study compared data from 2009 & 2010 and found that over time the percent of queries which were navigational was increasing. And even outside of the navigational queries, traffic was consolidating onto a smaller set of known domains over time due to user preference for known branded sites. Over time, as people build habits (like buying certain product categories from Amazon.com) the established user habits shift search query types.
Domain bias also affects how queries are categorized as navigational vs. informational. As user visits concentrate on fewer domains, former informational queries may now appear navigational. ... One common approach for determining whether a query is navigational is based on the entropy of its clicks. As domain bias becomes stronger, user visits are concentrated on fewer domains, even for informational queries. Algorithms for distinguishing between informational and navigational queries may have to be revisited in the presence of domain bias.
Once our habits are in place, even if the rankings shift a bit, it is hard to change our habits. So if the Amazon.com page ranks a couple spots lower but is still our go-to spot for a particular item, we will still likely click on that listing & give Bing or Google the signal that we like that particular result.
Branded Searches Replace Direct Navigation
The above noted increasing proportion of navigational searches was a trend noticed back in 2010. That was before the rise of mobile search, before Chrome & other web browsers replaced address bars with multi-function search boxes, etc. A few years back in the forums DennisG mentioned how a greater share of what were formerly direct visits to eBay became branded search queries. Search effectively replaced direct navigation (or typing in domain names) for many consumers.
And the consolidation of search volumes on large marketplaces has only increased over the years due to a broad array of factors. Smaller ecommerce businesses competed primarily via enjoying artificially high exposure in the search channel, but that has changed.
- user awareness of and preference for larger sites
- less weight on legacy search relevancy signals like link anchor text
- increasing penalties for smaller sites: manual penalties, Panda, Penguin, etc.
- greater weight on usage data & engagement-related relevancy signals
- larger search ad units further displacing the organic result set
- higher search ad prices killing the margins on smaller businesses with more limited inventory & lower lifetime customer values
- the insertion of vertical search ads in key areas like ecommerce
Traffic Consolidation
One of my old small ecommerce clients at one point outranked the brand he sold on their own branded keywords. Those were the days! :)
But in less than 5 years he went from being one of the largest sellers of that company (& over 10% of their sales volume) to having his sales shrink so much that he took his site offline. After there were 3 AdWords ads above the organic results with sitelinks, Google launched product listing ads & the branded site got 6 sitelinks, the remaining organic results were essentially pushed below the fold.
The above story has played out over and over again. You can read the individual stories or see it in the aggregate metrics: "Apart from Amazon—which has long spurned profits in favour of growth—most pure-play online retailers are losing market share, says Sucharita Mulpuru of Forrester Research."
To isolate the impact of navigational searches on the study, they only analyzed keywords where pages were seen as roughly similar relevancy. They had people rate the snippets without the domain names & then with the domain names, and the domain name itself had a significant impact. Anything which is a known quantity which we have experience with is typically seen as a lower risk option than an unknown. And search engines think the same way "A related line of research is on the bias of search engines on page popularity. Cho and Roy observed that search engines penalized newly created pages by giving higher rankings to the current popular pages." Of course, search engines try to correct for some such biases using things like a spike in search volume or a large diverse collection of new news stories to trigger query deserves freshness to rank some fresh pages from news sites.
For a search engine to rank a new page on an old trusted site there isn't a lot of risk. For a search engine to rank a new site they are taking a big risk in ranking a fairly unknown quantity: "While there is an increasing volume of content on the web and an increasing number of sites, search engine results tend to concentrate on increasingly fewer domains!"
The Risk of Vertical Aggregators (to Google)
Whereas they are taking minimal risk in ranking a page on Amazon.com or WebMD. The result on a large trusted site is likely to be good enough to satisfy a user's interest and is a risk-free option for search engines. In fact, the only risk to search engines in over-promoting a few known vertical sites is that they might reinforce the user preference to such a degree that they increase the power of the vertical search providers.
The leaked FTC memorandum on Google quoted some internal Google communications:
"Some vertical aggregators are building brands and garnering an increasing % of traffic directly (vs. through Google); ... Strong content is improving aggregator organic ranking.~ and generating higher quality scores, giving them more free and/or low CPC traffic; . . A growing% of finance & travel category queries are navigational vs. generic (e.g., southwest. com vs. cheap airfare). This demonstrates the power of these brands and risk to our monetizable traffic." "Vertical Aggregators taking higher share of last clicks before sale," and "merchants increasing % of spend on aggregators vs. Google"
The reaction to the above fear is incidentally why Google got hit by antitrust regulators in Europe. Some notes from that leaked FTC memorandum:
- "The bizrate/nextag/epinions pages are decently good results. They are usually well-format[t]ed, rarely broken, load quickly and usually on-topic. Raters tend to like them" ... thus they decided to ... "Google repeatedly changed the instructions for raters until raters assessed Google's services favorably"
- “most of us on geo [Google Local] think we won't win unless we can inject a lot more of local directly into google results” ... thus they decided to ... "“add a 'concurring sites' signal to bias ourselves toward triggering [display of a Google local service] when a local-oriented aggregator site (i.e. Citysearch) shows up in the web results”"
The above displacement of general web search with vertical search is one of the reasons I though brand-related signals might peak. That thesis was not correct. What what was incomplete in that analysis was "the visual layout of the search result page trumps the underlying ranking algorithms," something I was well aware of back in 2009, though I failed to realize Google was eventually going to force the brands to pay premium rates for their own branded keywords by inserting other ad types driven by alternative pricing metrics. Earlier attempts to get brands to pay for banners on their own branded terms failed to monetize as well as Google hoped.
Helpful, but Still Spam
Some of Google's remote rater guidelines have explicitly mentioned a variety of ways to disintermediate other aggregators. Perhaps the most egregious example was when Google suggested HELPFUL hotel affiliate sites shall be rated as spam, but they have also had other more subtle instructions. For example, they have mentioned when search results ask for a list of options that the rater could consider the search result page itself as that list of options. And then of course there are all of Google's vertical search offerings, YouTube, the Play store, the knowledge graph, and answers scraped from pages formatted as featured results.
Google's decisions to launch new features & displace the result set are not algorithmically driven, but are executive business decisions. Many of the ranking signals are designed primarily around anti-competitive business interests.
And while the big decisions are made by the executives, Google falls back on "the algorithm" anytime there are complaints: “The amoral status of an algorithm does not negate its effects on society.”
The above referenced Microsoft research paper on domain bias concludes with
Domain bias has led users to concentrate their web visits on fewer and fewer domains. It is debatable whether this trend is conductive to the health and growth of the web in the long run. Will users be better off if only a handful of reputable domains remain? We leave it as a tantalizing question for the reader.
Navigational Searches
The Promotion of Brands Expressed in User Habits
The above mentioned Microsoft research paper mentions "the existence of domain bias has numerous consequences including, for example, the importance of discounting click activity from reputable domains."
Google itself has to a large degree moved in the opposite direction. There are some search queries where an unbranded site with decent usage metrics but little brand awareness might require 500 or 1,000 unique linking domains to be able to rank somewhere on the first page of the search results. In some cases on that same SERP, a thin lead generation styled page with obtrusive pop ups & no inbound links on a large brand site will outrank the smaller independent site.
Without folding in engagement metrics, there is almost no way the ugly pop up ridden page on a big brand site would outrank that independent site with a far better on-page user experience.
While it may be cheap to try to fake some brand-related inputs at a smaller scale, it would be quite expensive to do it at a larger scale while making the profiles look natural, as many of the most popular keywords are navigational branded terms. The Google AdWords keyword tool shows popular keywords by category & with the the jobs and education category there are millions of monthly searches for branded terms like edmodo and cool math games.
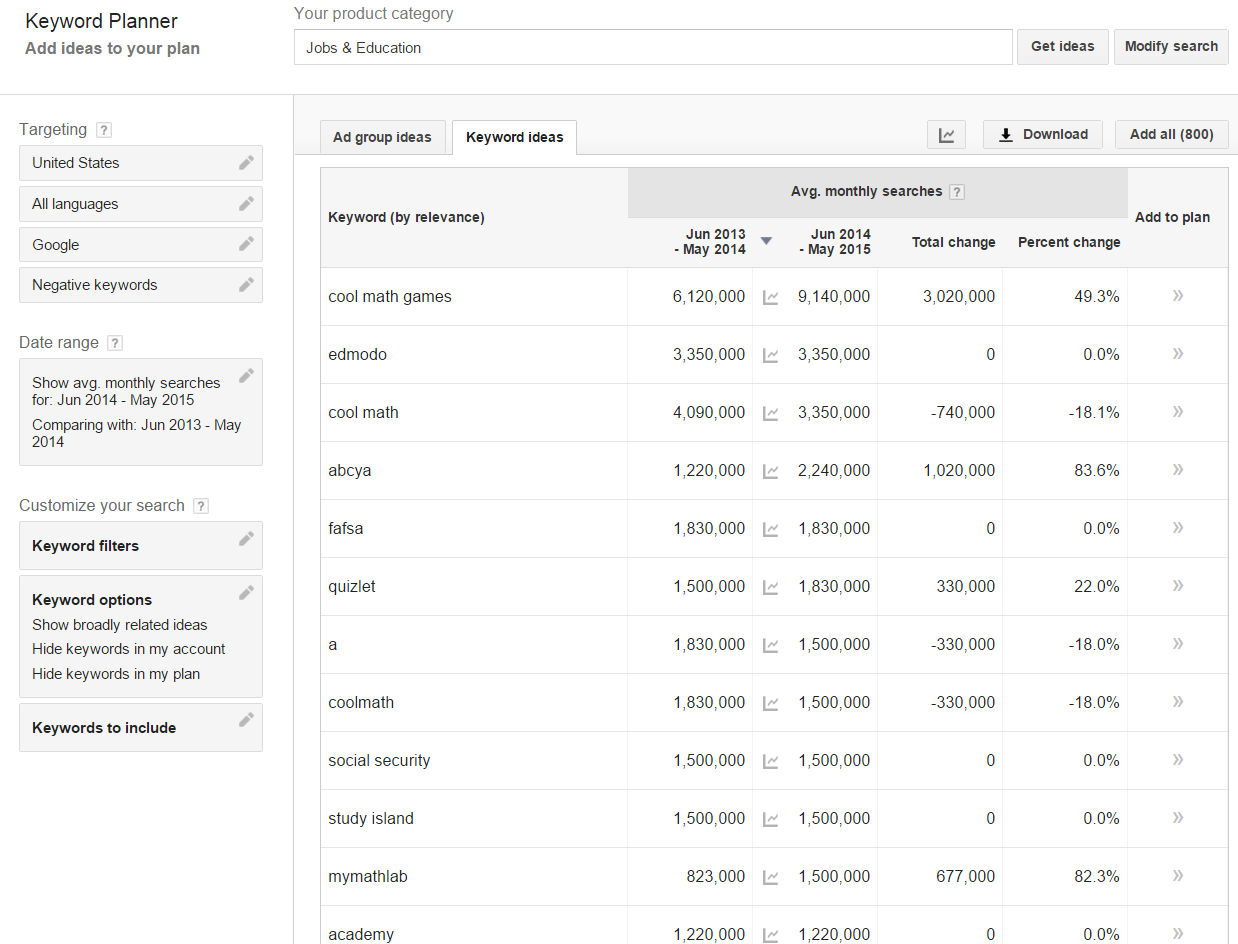
How prevalent are navigational queries or reference queries associated with known entities? Is there enough search volume there to create relevancy signals? According to Microsoft Research:
at least 20-30% of queries submitted to Bing search are simply name entities, and it is reported 71% of queries contain name entities.
Shortening Query Chains
Google uses navigational search queries as a relevancy signal in a number of ways. When the Vince update happened Google explicitly referenced it being associated with query chains. Part of the hint that query chains were at play was some of the larger social sites like Facebook were showing up as related queries where they wouldn't be expected to. As the social network was a common destination when people were done with other tasks, Google incorrectly folded a relationship in with Facebook and other search queries.
In 2009 Google applied for a patent named Navigational Resources for Queries. Here is an image from the patent.
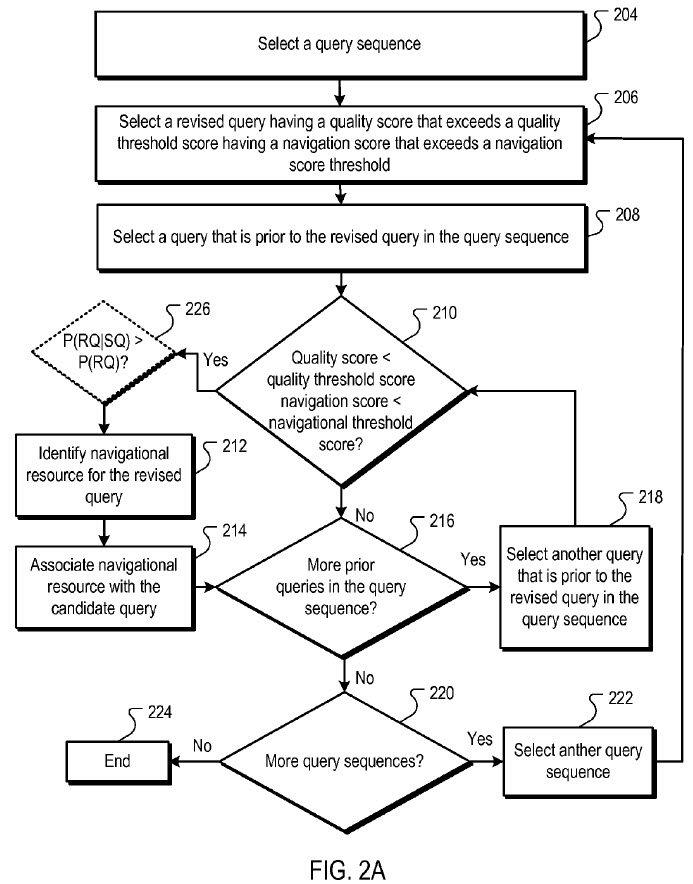
And the abstract states:
Methods, systems and apparatus, including computer program products, for identifying navigational resources for queries. In an aspect, a candidate query in a query sequence is selected, and a revised query subsequent to the candidate query in the query sequence is selected. If a quality score for the revised query is greater than a navigational score threshold, then a navigational resource for the revised query is identified and associated with the candidate query. The association specifies the navigational resource as being relevant to the candidate query in a search operation.
In the past Microsoft offered a search funnel tool which showed the terms people would search for after searching for an initial query.
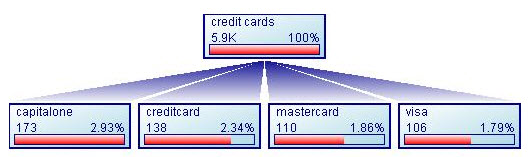
For searches where Google doesn't have much data they have less confidence in the result quality, so they try to shift people toward more common related queries. They do this in multiple ways including automated spell suggestions & using their dictionary behind the scenes to associate like terms with like meanings. This also has the benefit of increasing the yield of search ads as it makes it easier to return relevant ads & auction participants are pushed to compete on a tighter range of search queries.
While the above image only shows a single directional chain, some query refinement chains might have 3 or 4 or 5 steps in them, with searchers starting at a generic informational search and ending up at a navigational search query. Conceptually it might be something like:
- how to get a credit card
- best credit cards
- credit cards available to students with no credit
- top student credit cards
- Visa student card
Google can determine the associations of the queries based on sharing common terms or word stems or synonyms, the edit distance between the terms, the time between each query modification within a search session (less time between queries is generally seen as a greater signal of association), and if people typing a subsequent query are more likely to type that particular query after typing one of the related earlier queries.
Many people searching for [credit card] related terms eventually type a search query which contains Visa and/or MasterCard in it. Once Google determines Visa and MasterCard are relevant to topics like [top student credit cards] they can also re-run the same process and determine if they are also relevant to other queries earlier in the chain.
Other navigational search queries may be far more popular than Visa and MasterCard, but not as popular in the specific process or sequence. For example, if 3% of total global search volume is for a navigational term like Facebook, then Facebook.com will have a high navigational score and their links will also give them a high authority score. But if after completing the above mentioned credit card task, only 0.7% of people want to check out Facebook real quick, then Google should not try to associate Facebook into the above stream, because that 0.7% is less than the 3% of the total search market which the search query [Facebook] represents.
Facebook is a navigational query and Facebook.com is the navigational resource associated with that navigational query, but Facebook is not a navigational query relevant to credit card searches.
Google's work on understanding entities and word relations further augments their efforts to shorten query chains by allowing pages on authoritative sites to rank for many conceptually related longtail queries even if some of the words are not included within the page or in inbound link text pointing at the page. The downside of these algorithms is not just that they scrub away ecosystem diversity, but they also make it hard to find some background information about broad entities (say Google, Facebook, Amazon, etc.) because marginally related topical pages on the official entity site itself will outrank many third party sources writing about specific aspects of the entity or platform.
How does Google know if a query is navigational?
There are a variety of signals Google can use, including things like: domain name matching a keyword, anchor text distributions, quality & quantity of links to a site from unaffiliated domains, other ranked sites for a query linking to a specific site (inter-connectivity of the initial search result set / the topic referenced in Hilltop), percent of searches which conclude a search session, the click distribution among searchers for a query and the percent of search traffic into a site which contain a specific term. Navigational or branded searches tend to have many clicks on the top ranked results, whereas informational searches tend to have a more diffuse click profile deeper into the result set.
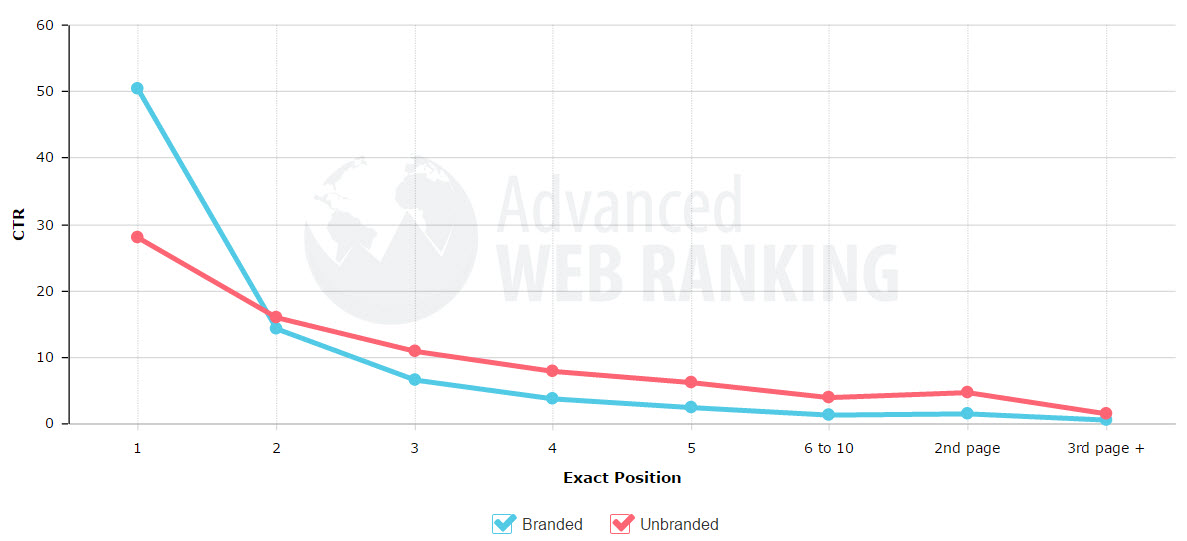
The last signal is probably the most powerful one for bigger brands. If millions of people are searching for something, almost all of them are selecting a specific site, and many of them are repeatedly selecting the same site - they are sending a clear message, saying "this is what I want."
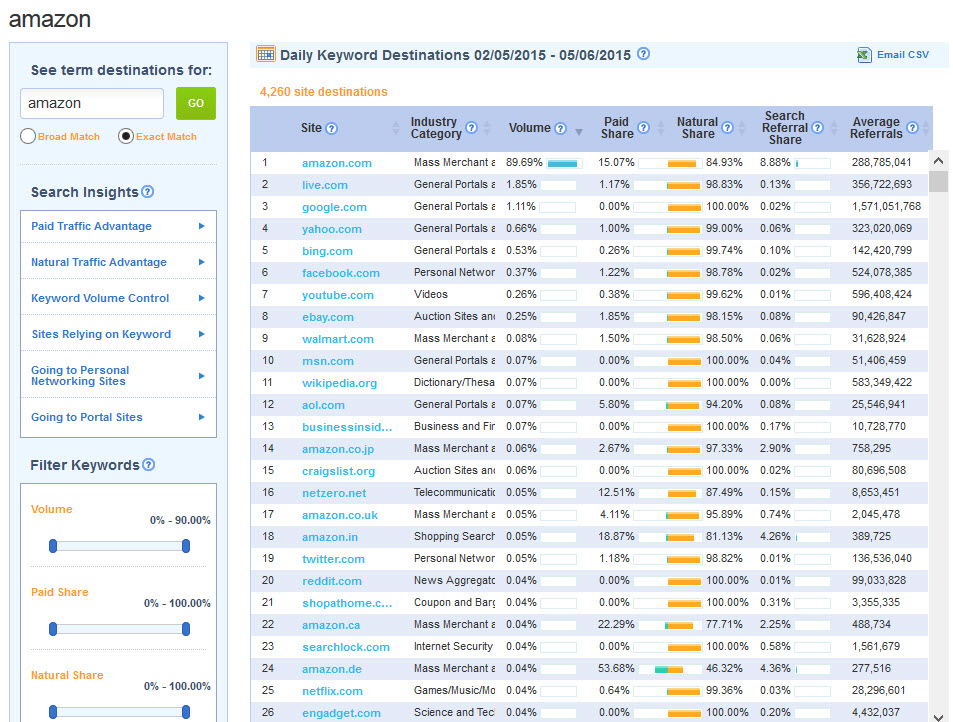
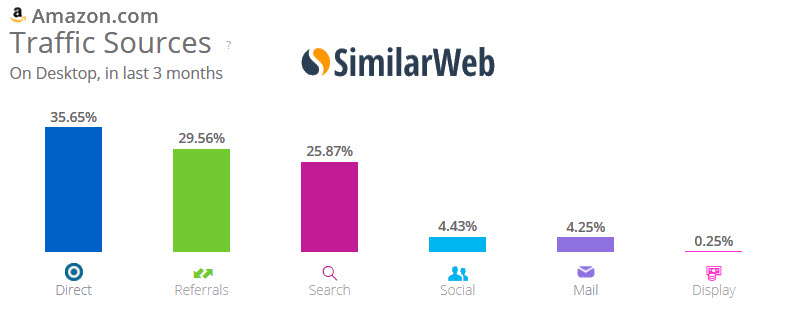
According to Compete.com, about 90% of the people in the US who type [amazon] into a search box end up clicking on Amazon.com. And that number likely skew significantly low of the true CTR.
- some searches are siphoned off by search boxes in the address bar & thus don't get reported as going through the search engines
- some of the other sites which show as the "next" click are broad web portals, which could mean things like people clicked the link to Amazon to open in a new window and then later did another search, or they clicked through some links which had some tracking redirects on them, or people clicked back into the SERP after they did a quick visit on Amazon (perhaps they did a quick visit to see the price of an item they were about to buy in a physical store & wanted to see if the cost savings of buying online were sufficient to justify waiting to get the item)
From the above Compete.com screenshot you can see almost 10% of the people in the US who visit Amazon.com from search do so by specifically searching for [amazon]. When the term is broad matched, that 10% jumps to about 20%. So not only are over 10 million people searching for Amazon each month, but then another 10+ million are searching for a variety of other queries like [Amazon.com Tide laundry detergent pods].
Generic vs Brand
The issue with brand-based signals in competitive markets where brand signals play a large role, is ot hard to be both a generic industry term and a brand name unless your product creates a new category: like Post-it, Kleenex & Zerox.
| Industry Generic | Brand |
| Auction.com, Auctions.com, OnlineAuction.com | eBay |
| Search.com SearchEngine.com | Google, Bing |
| Portal.com WebPortal.com | Yahoo!, MSN, AOL |
| Store.com OnlineStore.com | Amazon.com |
| Insure.com Insurance.com AutoInsurance.com CarInsurance.com | Geico, Progressive, AllState, Esurance |
The branded terms which are not generic can afford to advertise in many different mediums from humorous TV commercials or YouTube videos (like Geico does), banners across the web, social media ads, paid search ads, retargeting/remarketing ads, billboards, radio ads, etc. Any form of exposure which drives brand awareness and search volume then creates an associated relevancy signal.
But if you own a site like CarInsurance.com, even if you get a lot of people to search for the term you are targeting [car insurance] that is unlikely to count as a brand-related signal for your site, because Google can run many ads on that search and the site CarInsurance.com would only get a tiny minority of the search click volume, while the majority of it is monetized by Google.
Look how small I had to make the font to get CarInsurance.com to appear above the fold. That Google puts the result so far down the SERP is one indication they don't view the term [car insurance] as a branded term.
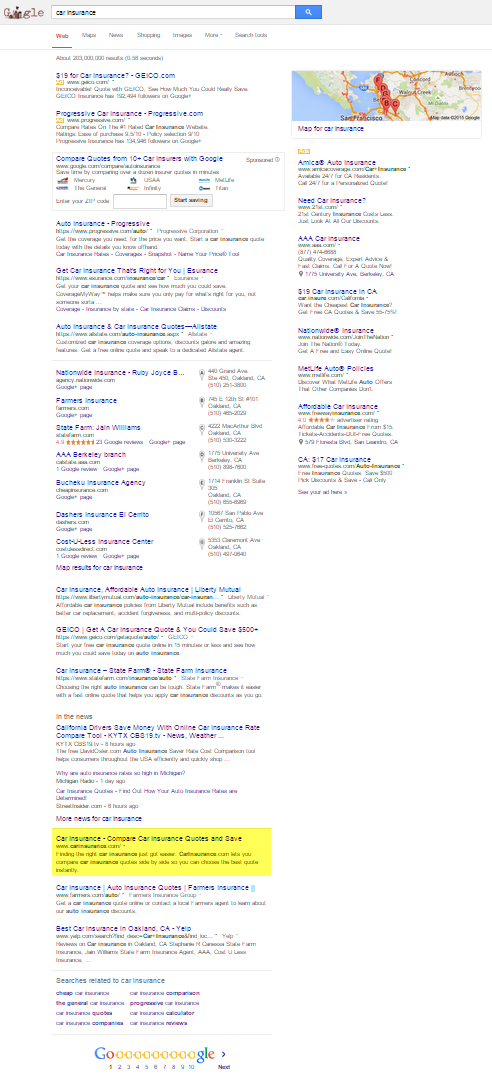
In most cases (with a few rare exceptions) Google won't consider that type of search term as having navigational intent UNLESS you run the words together...
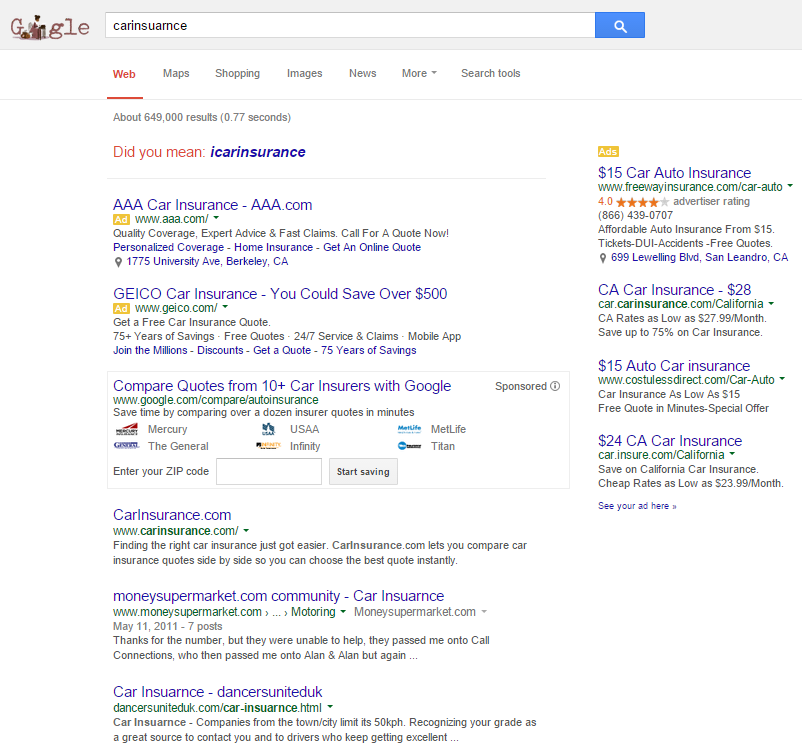
...or add the domain extension to the search...
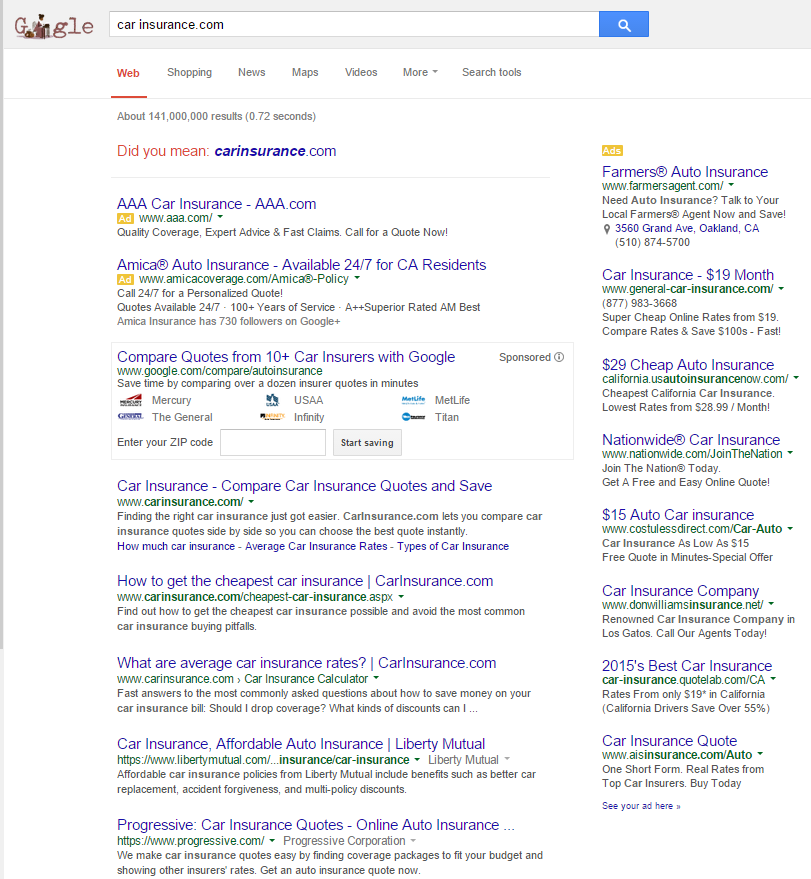
...or do both.
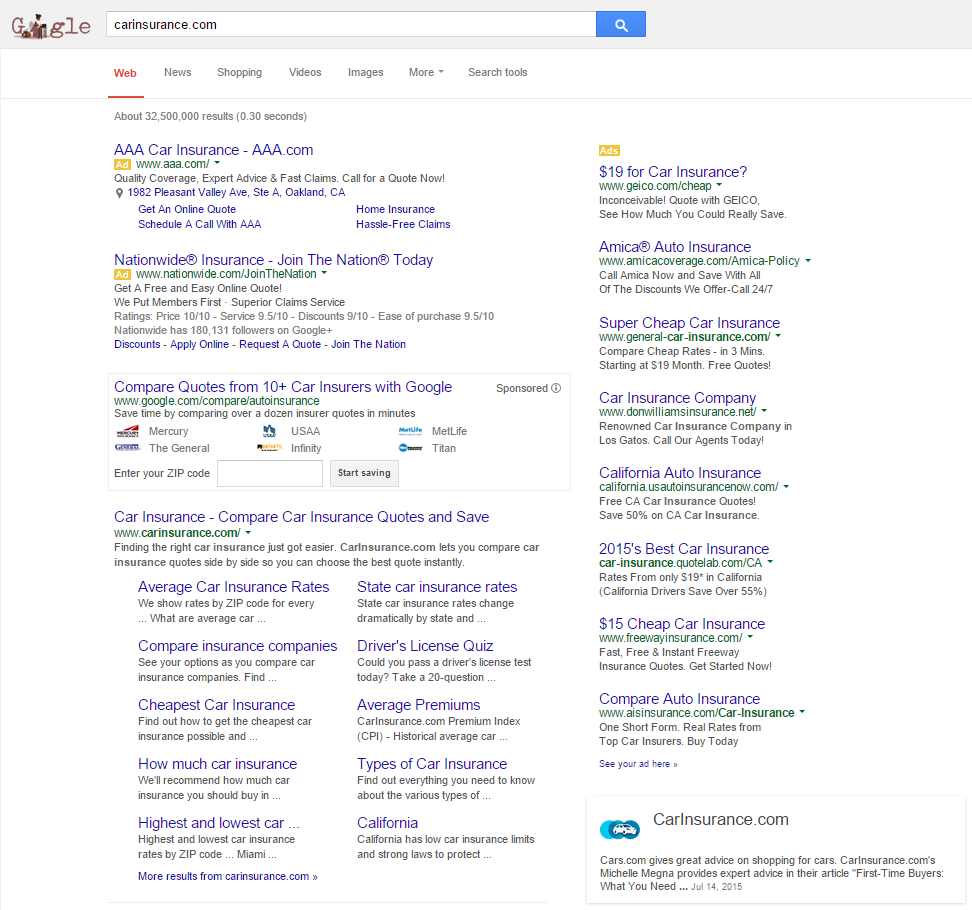
But in the current search ecosystem, few people who are searching for the generic term will run the words together or add the TLD to the search query. Fewer still will do both. And, even when they do, Google still aggressively places ads before the algorithmically determined navigational result.
You can see from the above search results how Google goes from viewing the query as industry generic in the first search, on through to considering potential navigational intent on the middle queries, on through to being certain of a navigational intent on the last query (as indicated by the sitelinks). But even when there is navigational intent, the term is so close to other industry terms that Google puts their AdWords ads and vertical search results above the organic search results. That means that even if you own that sort of domain name and try to do any sort of brand advertising, if you get people to search for you, you need them to search for the niche navigational variation with the words ran together & the TLD added over the core industry term, and even then you still have to pray they don't click on the ads above the organic search results.
In the modern search ecosystem there is almost no way for a site like CarInsurance.com to create the brand-related signals to outrank Geico on the core industry terms without accruing a penalty in the process (unless Google invests in them and doesn't enforce the guidelines on them). And even if they somehow manage to outrank them without accruing a penalty, they are still below a bunch of ads, and a negative SEO push could easily drive them into a penalty from there.
Before the Panda update the SEO process (even for exceptionally compet might look something like:
- general market research
- keyword research
- pick a domain name tied to a great keyword
- create keyword-focused content
- build exposure & awareness through organic search rankings
- use the profit generated to build more featured content and awareness
...but now with the brand / engagement metrics folding, the SEO process might look more like:
- general market research
- determine a market or marketing gap based on the strengths and weaknesses of competitors
- buy a brandable domain name which leans into the perception and messaging in terms of the point of differentiation
- create featured editorial built around pulling in attention and awareness
- use that brand awareness and loyalty to build keyword focused content targeting commercial terms
I think the person who summed up the shift best was Sugarrae when she wrote: "Google doesn’t want to make websites popular, they want to rank popular websites. If you don’t understand the difference, you’re in for one hell of an uphill climb."
And with Panda updates shifting to becoming slow rolling roll outs, it will become much harder to know what is wrong if one is riding the line.
Google as Aggregator, Disintermediating Niche Businesses & Review Sites
As mentioned in an earlier section, Google's remote rater guidelines mentioned when search results ask for a list of options that the rater could consider the search result page itself as that list of options. Google's goal is to shorten query chains as much as possible. This effectively squeezes out many of the smaller players while subsidizing some of the larger known brands. If they could have gotten away with stealing reviews in perpetuity, they would have quickly displaced Yelp and TripAdvisor too. Anything where there is online activity associated with scheduling offline economic behavior is something Google wants to own and displace others from. They'll start with some of the most profitable markets (hotels, flights, auto insurance, financial products, etc.) and then work their way down.
This squeeze is challenging for niche retail sites or other sites with a significant trust barrier but limited friction in their process which allows bigger competitors to compete at lower margins. Even if you have better product organization & presentation, many people who find what they want on your site are likely to buy it on Amazon because they already have an account there & it is hard to beat Amazon on pricing.
As Google promotes known brands across a broader array of search queries, they can use the end user clickstream data to determine if they are leaning on the signal too heavily, and adjust downward the rankings of brands where the association is an algorithmic mistake (as few searchers click on it) or associations which do not fit a user's needs for other reasons (for example, if Google ranks Tesco.com high in the United States for [baby milk] when the cost of shipping internationally would be prohibitive for most consumers, any consumer who clicks on that listing is likely to click back and then select a different listing).
Bing is also testing featuring brands in search results on generic search queries. Some of the tests they have done have included the brands in the right rail knowledge graph rather than in the regular organic search results.
Where We Are Headed
One of the above referenced patents mentioned how Google could fold navigational resources earlier into the search funnel, however Google can also use similar parallel signals for non-navigational search queries. The patent Methods and systems for improving a search ranking using related queries has an abstract which reads:
Systems and methods that improve search rankings for a search query by using data associated with queries related to the search query are described. In one aspect, a search query is received, a related query related to the search query is determined, an article (such as a web page) associated with the search query is determined, and a ranking score for the article based at least in part on data associated with the related query is determined. Several algorithms and types of data associated with related queries useful in carrying out such systems and methods are described.
Google has a variety of ways to determine if keywords are related.
- queries entered back to back
- queries entered with a short period of time between them
- queries which contain a common term
- edit distance between terms
- keyword co-occurrence in web documents
- n-gram data from their book scanning project
- clustered news articles & topics
- etc.
Google can estimate the similarity between keywords and then fold clicks data from documents ranking for parallel terms as a relevancy signal back into altering the rankings on the current keyword.
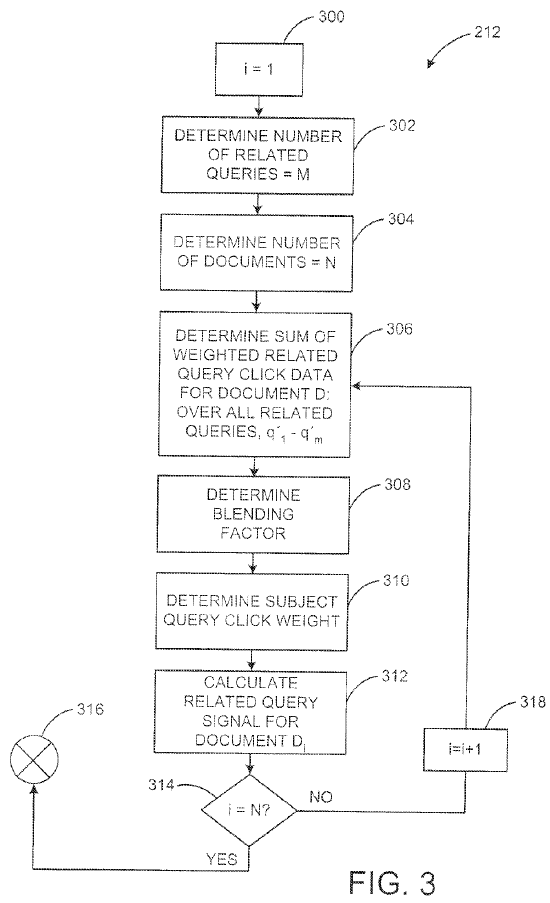
And, in addition to folding the weighted click data from related keywords back into the rankings of pages for the current term, Google can also use related terms to rewrite user search queries into more popular search queries where Google has a higher confidence in the result quality by substituting related terms. There are dozens of different patents like this, this or that on modifying search queries to better match user intent.
Google can also use the click stream data & topic modeling of selected pages to assign the dominant user intent for a keyword with multiple potential intents. Here is an image from their patent on propagating query classifications.
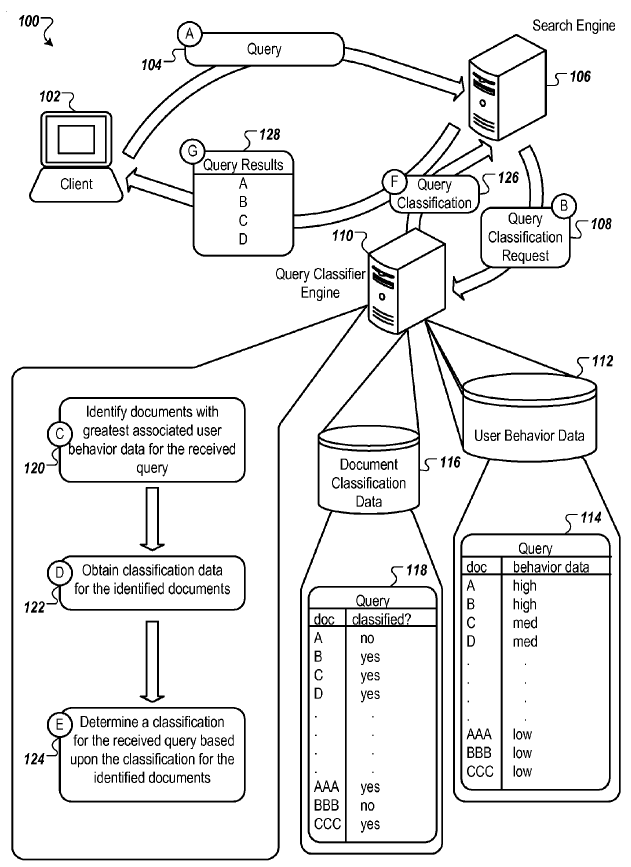
Each additional layer of data transformation surfaces more layers of confirmation bias, while the unknown has more new ways to become less known!
Niche sites will continue dying off:
there’s no reason why the internet couldn’t keep on its present course for years to come. Under those circumstances, it would shed most of the features that make it popular with today’s avant-garde, and become one more centralized, regulated, vacuous mass medium, packed to the bursting point with corporate advertising and lowest-common-denominator content, with dissenting voices and alternative culture shut out or shoved into corners where nobody ever looks. That’s the normal trajectory of an information technology in today’s industrial civilization, after all; it’s what happened with radio and television in their day, as the gaudy and grandiose claims of the early years gave way to the crass commercial realities of the mature forms of each medium.
As users spend more times on social sites & other closed vertical portals which leverage their walled gardens to have superior ad targeting data, media creators will follow audiences, and TV may well become the model for the web as small businesses are defunded & audiences move on.
Eventually they might even symbolically close their websites, finishing the job they started when they all stopped paying attention to what their front pages looked like. Then, they will do a whole lot of what they already do, according to the demands of their new venues. They will report news and tell stories and post garbage and make mistakes. They will be given new metrics that are both more shallow and more urgent than ever before; they will adapt to them, all the while avoiding, as is tradition, honest discussions about the relationship between success and quality and self-respect.
...
If in five years I’m just watching NFL-endorsed ESPN clips through a syndication deal with a messaging app, and Vice is just an age-skewed Viacom with better audience data, and I’m looking up the same trivia on Genius instead of Wikipedia, and “publications” are just content agencies that solve temporary optimization issues for much larger platforms, what will have been point of the last twenty years of creating things for the web?
Panda - Comparing Navigational Searches to a Site's Link Profile
Common Ways to Generate Awareness Signals
Google has advertised that buying display ads drives branded search queries.

If display advertising provides that type of lift, then advertising directly in the search results for relevant terms builds consumer awareness & leads to subsequent branded search volume.
As search engines have replaced address bars with search boxes, search has replaced direct navigation for an increasing share of the population. Any large organization will generate some amount of branded search volume by virtue of its size. Some examples below:
- employees may need to log in regularly to see important company news, changes to work policies, updates to their work schedules, check company email, etc. (this also applies to other organizations like non-profits, colleges, and military organizations)
- affiliates, suppliers & other business partners may need to log into sections of a site to find fresh promotions or product inventory needs
- publicly traded companies have employees with stock options, investors, stock analysts, etc. who regularly read their financial news and tune into their quarterly reports
- a person who regularly logs into their bank account or pays their utility bills online will likely perform many branded search queries (the risk of getting hacked by typing a URL incorrectly makes people more likely to visit some types of sites directly through the search channel)
- offline stores are like interactive billboards where you can buy products, or return/exchange broken products
- newspapers can invite readers to access extended versions of stories online & offer other benefits online
- coupon circulars, sweepstakes contests, and warranty polices can drive consumers to websites
- email lists, having a following on social channels, etc. can drive subsequent search volume (especially given how people consume media across multiple devices like their cell phone or their work computer & may prefer to transact on desktop computers while at home)
- etc.
Almost any form of awareness bleeds over to better aggregate engagement metrics.
Links Without Awareness = Trouble
The day Panda rolled out, my theory was "perhaps Google is looking at somehow folding brand search traffic into a signal directly in the web's link graph?"
A site which is held up by "just links" but has no employees, few customers, no offline stores, no following on social, no email list, almost nobody looking specifically for it, etc. may have a hard time creating enough usage signals to justify the existence of their link profile.
Bill Slawski was one of the first SEOs to cover the panda patent, named Ranking Search Results.
One of the methods includes determining, for each of a plurality of groups of resources, a respective count of independent incoming links to resources in the group; determining, for each of the plurality of groups of resources, a respective count of reference queries; determining, for each of the plurality of groups of resources, a respective group-specific modification factor, wherein the group-specific modification factor for each group is based on the count of independent links and the count of reference queries for the group; and associating, with each of the plurality of groups of resources, the respective group-specific modification factor for the group, wherein the respective group-specific modification for the group modifies the initial scores generated for resources in the group in response to received search queries.
Prior to the Panda update, Google would primarily count positive metrics, and typically ignore most other metrics. Panda was really the first widespread algorithmic situation where some typical relevancy signals which counted for you could start counting against you. Key to Panda was the combination of folding in usage data and analyzing the ratio of various signals. Suddenly, relying too heavily on a particular signal (like links) while failing to build broad consumer awareness could then make the links count against you rather than counting for you.
Here are a couple images from the Panda patent. The first shows how they compare unique linking domains from unaffiliated sites versus branded or navigational reference search queries which imply the user is looking for a specific site.
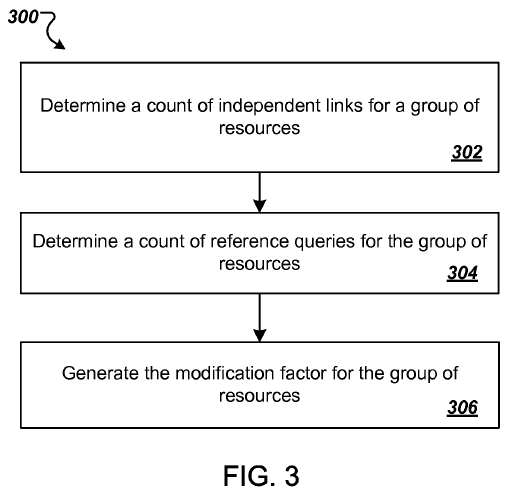
The second image shows that if the query is navigational they do not enable Panda to lower the ranking of the top ranked site, that way even a site hit by Panda is still allowed to rank for its brand-related search terms (provided those brand-related terms are not also industry generic terms & that there isn't a larger + more popular parallel parallel brand using the same name). This allows Google to aggressively penalize sites without making people realize they are missing, because they still show up when people specifically search for them.
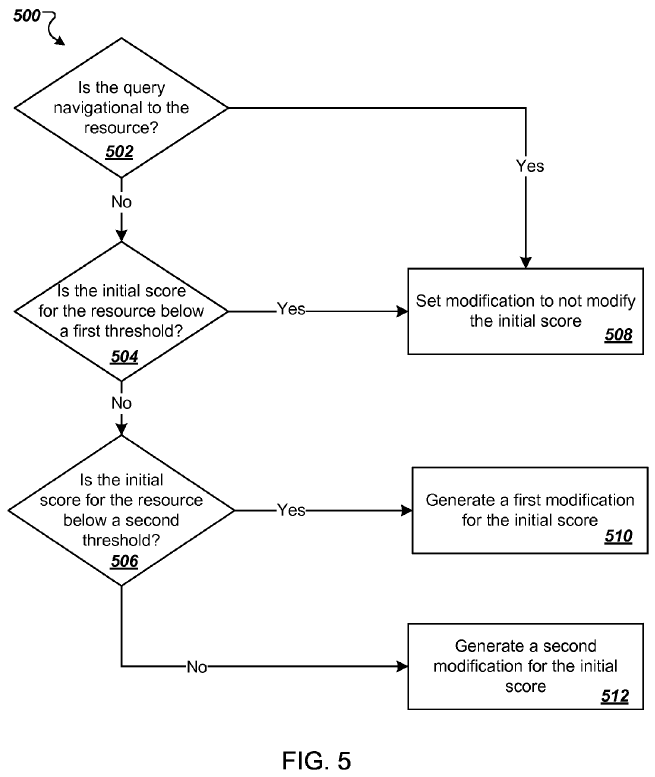
Panda can impact sites positively, negatively, or have a roughly neutral impact.
- If lots of people are searching for your site (relative to the link count) then you can get a strong rank boost. A site like Amazon, which has many people looking for it, gets a ranking boost.
- If you have a decent number of navigational searches & a decent number of links your site's ranking scores might not change (though other sites around your site may still rise or fall due to positive or negative Panda-scores). Many sites in this category still saw significant ranking shifts due to sites like Amazon.com, eBay.com & WalMart.com rising.
- If your site has few people looking for it (relative to the size of the link profile) then your site's ranking scores are negatively impacted by Panda. A site like Mahalo, which was a glorified scraper site propped up by link schemes & didn't publish particularly useful content, saw its rankings tank.
Google can also normalize the modification factor so they apply them differently to sites of different sizes and levels levels of awareness.
Panda Evolves
Some smaller sites which were not hit by the first version of Panda were not hit because Google first wanted to go after the most egregious examples & then as Google gained more confidence in their modeling they were able to apply the algorithm with increased granularity.
In one speech Matt Cutts mentioned that Panda sort of worked like a thermostat, so while the above 3 buckets exist, there can be additional buckets, or degrees of impact within each bucket.
The Panda patent mentioned scoring working based on "a group of resources."
The initial version of Panda's worked at a subdomain level. When HubPages highlighted anti-trust related concerns over the change, Matt Cutts gave them the advice to have their individual authors publish content on their own subdomains, which made it easier for Google to create author-specific ratings. Some spammers took advantage of the subdomain-related aspect by rotating subdomains each time Google did a Panda update, though Google eventually closed that hole. Google later adjusted Panda to allow more granular operation down to tighter levels beyond subdomains, like at a folder level.
At some points in time Google has mentioned Panda was being folded into their main algorithm, that it was automatically updated, that it was updated in real time, etc. But they later walked back some of that messaging and referenced that the computationally expensive process had to be manually run. It is run offline & is not frequently updated, much to the chagrin of SEOs.
And as people have become more aware of some of the types of signals used by Panda, Google has resorted to updating Panda less frequently, in order to make manipulating the signals more expensive & to add friction to client communications for those selling recovery services. To add further friction, Google frequently promises "update coming soon" and then falls back on "technical issues."
The Golden Ratio: Brand Searches vs Total Search Traffic
The concept of comparing ratios of signals from the original Panda patent also appeared in some follow up patents by Google's Navneet Panda.
Once again, Bill Slawski was one of the first SEOs to analyze another Navneet Panda patent named Site Quality Score.
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for determining a first count of unique queries, received by a search engine, that are categorized as referring to a particular site; determining a second count of unique queries, received by the search engine, that are associated with the particular site, wherein a query is associated with the particular site when the query is followed by a user selection of a search result that (a) was presented, by the search engine, in response to the query and (b) identifies a resource in the particular site; and determining, based on the first and second counts, a site quality score for the particular site.
The primary objective of this patent is to once again leverage navigational or brand-related reference queries as a relevancy signal, but this time it is done by comparing the ratio of a.) unique brand-related search keywords to total keyword count associated with a site; and b.) search traffic from those branded queries to overall search traffic into a site.
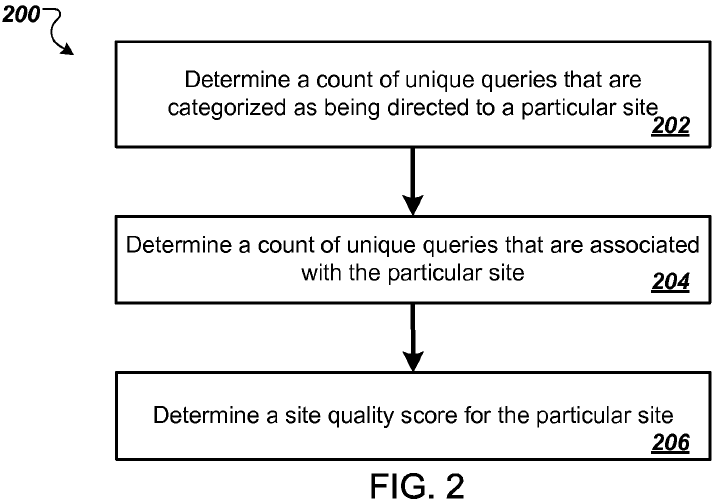
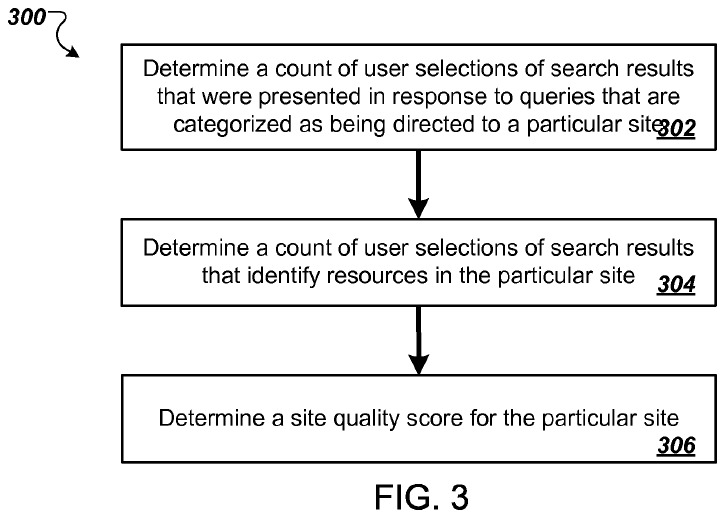
What this sort of patent does is subsidize any site which has a well known brand, while punishing sites which try to build a broad-base of longtail search traffic without investing in brand building.
- Losing: Sites which aim to offer a quick answer without making a strong impression (or sites which try to trick people into clicking on ads while serving no other purpose) lose. Sites offering nothing unique lose. Sites which are generic and undifferentiated lose. Sites with a poor user experience lose.
- Winning: Sites which have broad consumer awareness win. Sites which have deep immersive user experiences which make people want to register accounts on them and go back to them frequently win. This sort of signal once again benefits sites like Amazon.com.
If you manage to rank well, but almost nobody repeatedly visits your site or actively seeks you out, then you get hit. If you have broad awareness from other channels or the people who find your site via search keep coming back to it, then you win.
Signal Bleed
It makes sense that search usage is one of Google's cleanest signals to use, since they own the user experience & can directly track when things fail. The above patent mentions (brand-related & navigational) reference queries as a signal. But there is no reason Google couldn't look at other data sources for related signals. A Google engineer mentioned Google looks at app usage data for recommending apps. Similarly, Google could use the Chrome address bar to augment some of the brand-related search query data.
Do more people visit your site directly rather than via search? Seeing a bunch of logged in Chrome users repeatedly visit your site is a sign of quality, so Google can lean into that direct traffic stream as a signal to subsidize allowing your site to rank better.
Estimating New Sites
The above sorts of ratios are easy to use on existing well-established sites. But they don't work well on a brand new site which has not yet earned a strong rank & does not yet have many inbound links.
Bill Slawski mentioned another Navneet Panda patent on Predicting Site Quality.
In some implementations, the methods [for predicting a quality score] include obtaining baseline site quality scores for multiple previously scored sites;
- Generating a phrase model for multiple sites including the previously scored sites, wherein the phrase model defines a mapping from phrase specific relative frequency measures to phrase specific baseline site quality scores;
- For a new site that is not one of the previously scored sites, obtaining a relative frequency measure for each of a plurality of phrases in the new site;
- Determining an aggregate site quality score for the new site from the phrase model using the relative frequency measures of phrases in the new site; and
Determining a predicted site quality score for the new site from the aggregate site quality score.
Here are a couple pictures from that patent.
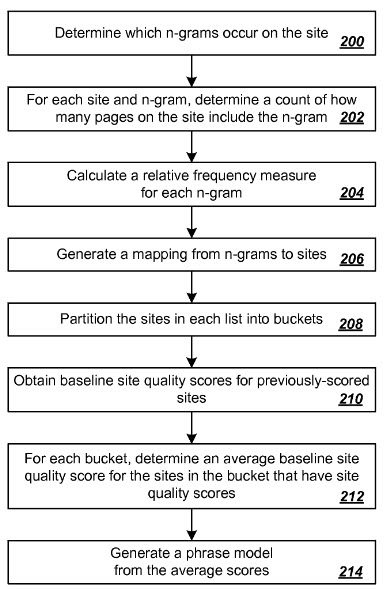

Google views most new sites with suspicion: guilty until proven innocent. If another site doesn't have any pulse of consumer demand and awareness, then if it primarily recycles content already available elsewhere online, Google probably doesn't want the additional duplication in their search ecosystem.
A new site which has an n-gram footprint similar to other sites which were deemed to be of lower quality may get hit due to on-page similarities. Think of...
- using the same exact product feed to auto-generate thousands of pages similar to thousands of other low quality duplicative affiliate sites which don't add any value, or
- a new & unknown merchant who sets up a new shop using default product descriptions while adding nothing else to the page (to Google an empty store full of recycled content is every bit as bad as a run of the mill affiliate & they've even hit some ecommerce networks of sites with doorway page penalties), or
- scraping an RSS feed which is scraped by thousands of other scraper sites, or
- recycling a bunch of crappy press releases, or
- using free content from article databases Google has already torched, or
- creating a site built on private label rights (PLR) content
- other forms of low-quality duplicate content
All Google would need to do to make such a system work is whitelist a few source exemptions (and such whitelists could be algorithmically generated based on having minimum trust-signal thresholds) & then other players syndicating Wikipedia, DMOZ, Amazon.com affiliate listings, and other affiliate feeds and such could easily automatically smoke themselves.
Many other sites using the same (cheap, easy, fast, scalable) content sources & content will have already been penalized by Panda, algorithmic link-based penalties, or manual penalties. Their site's lack of consumer awareness & engagement (it is hard to differentiate an offering when it is a copy of a widely freely available piece of content) combined with a similar footprint makes it easy for Google to choose not to trust parallel newer sites unless they manage to vastly differentiate their profiles from the untrusted sites.
In the past Google has mentioned they moved some aspects of their duplicate detection process earlier in the crawl cycle. In addition to using the above n-gram data for determining estimated quality, they can use that same sort of data for things like flagging sites for manual reviews, and other algorithmic processes like duplicate detection & determining which canonical source they want to rank.
Before Panda launched, sometimes I would let "meh" content get indexed while it was still staging, figuring it would take a bit of time to rank & I'd get around to fixing/formatting/improving it before it did. However over the past few years I've tried to be much more cautious with what I let in the index & try to ensure it is ready to go from day one. A lot of writing ends up being quite keyword dense due to many freelance writers being trained as that being the best way to do things from SEO experience over the years. If you work with a few writers frequently you can ensure that isn't a problem, but anyone ordering loads of content is likely going to get a lot of keyword dense repetition.
If you have enough trust built up (high-quality links, repeat visitors, branded searches, etc.) you can be an outlier many ways over in many areas & still rank fine. But if you don't have those signals built up (and backed up by years of high ratings from Google's remote raters), then the more your profile is aligned with other sites Google is demoting the more likely you are to step into an automatic demotion.
Aging a New Site: The Golden Ratio, Part 2
Prior to panda the idea of age-based trust and building a site to start the aging process was quite wise. But with panda & penguin active, you have to think about ratios with everything you do.
If you have a small enough footprint, sure start the aging process. But the more aggressively you scale things, the more aggressively you must scale awareness building in conjunction with link building and content building.
- ratio of quality links to low quality links
- ratio of branded anchors to keyword rich anchors
- recent rate of link acquisition compared to past link acquisition
- ratio of externally supported pages to unsupported pages
- ratio of links to branded or navigational searches
- ratio of total search visits to branded or navigational searches
- ratio of traffic from search vs traffic from other channels
- ratio of new visits to repeat visits
- ratio of your CTR when your site ranks compared to other sites which rank at that same position for that keyword
- ratio of higher quality keywords you rank for versus lower quality keywords (and the quality of other sites with a similar keyword ranking skew/footprint)
- the ratio of long click visitors on your site (search visitors who stay on your page for an extended period of time without clicking back to Google) versus short click visitors (those who quickly go back to Google)
- ratio of search visitors to your site to the search visitors to your site that click back to Google and then click onto another listing
- ratio of unique content to duplicated content (and the average quality of the majority of other sites which have published that same duplicated content)
- ratio of keyword density within the content (and the average quality of the majority of other documents with a similar keyword density)
- ratio of the main keyword in your content versus supporting related concepts (and the average quality of the majority of other documents with a similar footprint)
- how well your supporting phrases are aligned with those in other top ranked documents
- freshness of your document & the frequency your document is updated (when compared against other top ranking documents for the same keywords)
- etc.
Some shortcuts in isolation may work to boost a site's exposure, but a site which takes many shortcuts in parallel is likely to stand out as a statistical outlier & get classified as being associated with other sites which have already been demoted.
The Trap
By 2010 (even before Panda rolled out) it became clear Google was going to lean hard into setting traps & tricking SEOs into suffocating from negative feedback spirals.
So long as a site's owner is focused exclusively on the organic search channel (& is not focused on building awareness via other channels) then the penalties can almost become self-reinforcing. Webmasters chasing their own tails are not focused on making progress in the broader market. Until the webmaster finds a way to create demand and awareness which then feeds through as branded search queries & user habits, it can be hard to recover.
Many people who are hit by Panda quickly rush off and start disavowing links, but those efforts are removing relevancy signals & if they get rid of good links they are only further lowering their awareness in the marketplace (rather than focusing on building awareness). The only sustainable long-lasting solution is creating demand and awareness. And if your organic search performance has a dampener on it, that means you need to (at least temporarily) focus awareness-building marketing strategies on other channels.
There might be a variety of on-site clean up issues which need to happen in terms of duplication, usability, and so on. But for many sites to recover from a Panda hit you also have to build awareness elsewhere.
General Usage Data Usage
Usage Statistics
Google has a patent named Methods and apparatus for employing usage statistics in document retrieval which is somewhat related to the concepts behind DirectHit. It mentions folding in general web usage data into the relevancy algorithms. The abstract reads:
Methods and apparatus consistent with the invention provide improved organization of documents responsive to a search query. In one embodiment, a search query is received and a list of responsive documents is identified. The responsive documents are organized based in whole or in part on usage statistics.
Here are a couple images from the patent which show the rough concepts:
- the number of visitors to a document (based in-part on cookies and/or IP address)
- the frequency of visits to a document
- methods of filtering out automated traffic & traffic from the document owner/maintainer
- weighing the visit data differently across different geographic regions to localize the data to the user (and perhaps weighing other data sets differently to count data more from browsers or user account types which they have more data on and a better trust in the signal quality)
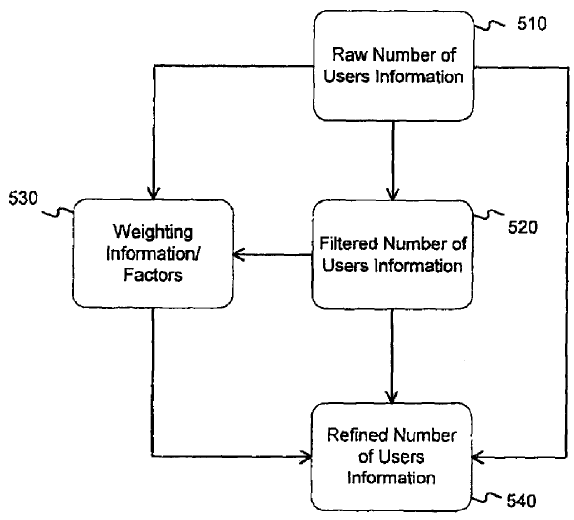
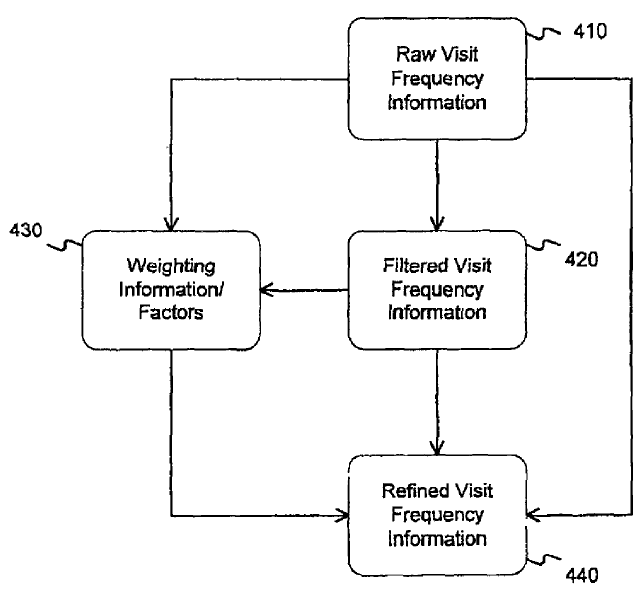
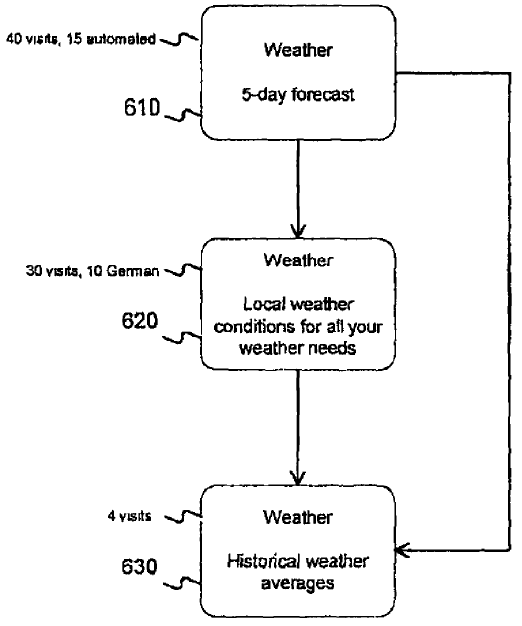
Rather than looking at the data on a per-document basis they can aggregate the information across a site, so that repeat visits to a home page of a news site or some other interactive site could in turn help subsidize the rankings of internal pages on that same site. Here is a description of one implementation type:
In one implementation, documents are organized based on a total score that represents the product of a usage score and a standard query-term-based score (“IR score”). In particular, the total score equals the square root of the IR score multiplied by the usage score. The usage score, in turn, equals a frequency of visit score multiplied by a unique user score multiplied by a path length score.
The frequency of visit score equals log 2(1+log(VF)/log(MAXVF). VF is the number of times that the document was visited (or accessed) in one month, and MAXVF is set to 2000. A small value is used when VF is unknown. If the unique user is less than 10, it equals 0.5*UU/10; otherwise, it equals 0.5*(1+UU/MAXUU). UU is the number of unique hosts/IPs that access the document in one month, and MAXUU is set to 400. A small value is used when UU is unknown. The path length score equals log(K−PL)/log(K). PL is the number of ‘/’ characters in the document's path, and K is set to 20.
In addition to looking at the recent unique visitor count and visit frequency, Google can also compare it against historical data to determine if the document is becoming more or less popular with users over time.
Presentation Bias
Google published a research paper titled Beyond Position Bias: Examining Result Attractiveness as a Source of Presentation Bias in Clickthrough Data.
In the paper it mentions how aspects of a snippet like word bolding in the title or description, title length, better keyword matching, and other similar factors can impact a document's perceived relevancy. They state the following:
A particularly illuminating study by Clark et al. [6] found that click inversions (when a lower ranked document receives more clicks than a higher ranked one) cannot be entirely explained by the lower ranking document being more relevant. They found that click inversions tend to co-occur with additional factors such as lower ranked documents having comparatively more matching query terms in the titles.
This leads me back to the Matt Cutts quote on algorithmic updates highlighted near the beginning of this article: "we got less spam and so it looks like people don't like the new algorithms as much."
Aggressive SEOs are likely to use the target keyword terms in their page titles. Some may repeat the terms or use multiple variations. But many of the documents which Google desires to rank are journalistic pieces which glancingly reference a term while having a headline which is more catchy to a casual reader than someone who is specifically searching for a keyword. An article from Steve Lohr complaining about the keyword bias of search engines was written in the New York Times back in 2006 using the title This Boring Headline is Written for Google.
In the paper they also mention how search engines can account for position bias (or the nature to click on the higher listed results) by using something called fair pairs, where they swap the order results 1 and 2 or 2 and 3 and then track how clickthrough rates change when results are switched.
Since users typically scan results in rank order, one can reasonably interpret clicks on a lower ranked result as implicit user preference feedback over an unclicked higher ranked results. One way to control for position bias is by randomly showing two adjacent results in either the original or swapped order. Since both results appear at the both positions equally often (in expectations), then intuitively, we can simply count clicks to determine relative preference. We use the term Fair Pair to denote the pairing of two rank-adjacent results.
When they test fair pairs, they do not test altering the first ranking on navigational queries.
Since that paper was published, some search engines have moved away from using keyword bolding in the search results. Google currently does not use bolding in their search results. Yahoo! uses bolding on their search ads but does not use them on their organic search results.
Rank Auditioning
Some websites which have insufficient link equity & usage data to justify a consistent top ranking on competitive keywords may still be tested by search engines to see how they perform. I believe the term which is commonly used to describe this is "auditioning." Search engines haven't described the audition process in detail, but I have seen results where a newer site which ranked on page 5 or 6 suddenly ranked at position #2 or #3 for a short period of time. Presumably when Google does that, they are collecting user response data from end users and tracking that result similarly to how they normally track fair pairs. If users respond well to the newly ranked site then the site can continue to rank well. If users don't respond positively to it, then sliding back down the result set it goes.
Counting Clicks: Implicit User Feedback
Following up on the above mentioned research paper, Google has a patent on Modifying Search Results Based on Implicit User Feedback. The abstract reads
Systems and techniques relating to ranking search results of a search query include, in general, subject matter that can be embodied in a computer-implemented method that includes determining a measure of relevance for a document result within a context of a search query for which the document result is returned, the determining being based on a first number in relation to a second number, the first number corresponding to longer views of the document result, and the second number corresponding to at least shorter views of the document result; and outputting a measure of relevance to a ranking engine for ranking of search results, including the document result, for a new search corresponding to the search query.
Here are images from the patent highlighting the above process
At the core of implicit user feedback is letting people vote with their clicks:
User reactions to particular search results or search result lists may be gauged, so that results on which users often click will receive a higher ranking. The general assumption under such an approach is that searching users are often the best judge of relevance, so that if they select a particular search result, it is likely to be relevant, or at least more relevant than the presented alternatives.
...
User selections of search results (click data) can be tracked and transformed into a click fraction that can be used to re-rank future search results. Data can be collected on a per-query basis, and for a given query, user preferences for document results can be determined.
The Long Click
Getting clicks to your site is only half the battle. Search engines can measure dwell time, which is how long it has been since a searcher has clicked a result before they return to the search result page. In fact, in 2011 Google included a "block all site.com results" message within the search results near listings when you clicked back into the search result page quickly (and thus had a short dwell time), though they eventually removed that feature when they wanted to promote Google+.
If someone clicks on your site and then quickly clicks back to Google to look at something else (also known as pogosticking), they are first telling Google "I want this" and then quickly telling Google "no, I didn't want that, I want something else."
If they click on your page & don't go back to Google they are telling Google your page fit their needs.
Here is a video where Jim Boykin explains pogosticking.
Bill Slawski wrote a great post about the long click in which he opened by quoting Steven Levy's In the Plex: How Google Thinks, Works, and Shapes our Lives
"On the most basic level, Google could see how satisfied users were. To paraphrase Tolstoy, happy users were all the same. The best sign of their happiness was the "Long Click" — This occurred when someone went to a search result, ideally the top one, and did not return. That meant Google has successfully fulfilled the query."
Google looks at post-click user behavior in AdWords as an input which helps drive their quality scores, which determines ad pricing. If they are using it as a core signal to price ads in their ad auction, there's no way they would decide not to use it in organic search.
What sorts of pages have short clicks, followed by the searcher quickly clicking on a different listing? Those which...
- promise something but fail to deliver on it (be it an answer to a question, a product which is out of stock, an expired coupon code, a reviews page with no actual reviews on it, claim to represent a recent news topic but cover
- an older story, promised content hidden behind a registration wall or pay wall, etc.)
- are broken or don't load (major HTML errors, crashing browsers, etc.)
- are so ad heavy it is hard to find the content (interstitial ads, ads on top of the content, pop ups, in-text ads, etc.)
- have other major credibility issues (spelling errors, poor formatting, poor usability, inconsistent design, etc.)
What sort of pages have long clicks, followed by the searcher either not returning to Google, or returning to Google much later to complete a different task? Those which...
- help the user complete their goal
- have good usability
- seem trustworthy
- offer the solution to the user's needs directly, or if they don't offer the solution directly they link to other sources which provide better information than what was available in the search results from other providers
The benefit of looking at the ratio of long clicks to short clicks is it helps overcome presentation bias and domain bias and many other forms of user bias.
- If a user thinks a result looks good but it ends up being garbage, they will click right back to the search results. So comparing the long clicks against the short clicks helps offset the bait-n-switch factor.
- If a user wants to buy an item and trusts a merchant to offer it but that merchant is out of stock, they will click right back to the search results.
- If a site is generally liked by users, but is a poor match due to some relevancy signal bleed (like ranking a page for the wrong location), the short clicks give Google a negative ranking signal feedback which helps them rank alternative pages instead.
The introduction section earlier in this article quoted Google's Tom Kershaw
“It’s not about storage, it’s about what you’ll do with analytics. Never delete anything, always use data – it’s what Google does.” “Real-time intelligence is only as good as the data you can put against it,” he said. “Think how different Google would be if we couldn’t see all of the analytics around Mother’s Day for the last 15 years.”
The patent states:
The recorded information can be stored in the result selection log. The recorded information can include log entries that indicate, for each user selection the query (Q), the document (D), the time (T) on the document, the language (L) employed by the user, and the country (C) where the user is likely located (e.g., based on the server used to access the IR system). Other information can also be recorded regarding user interactions with a presented ranking, including negative information, such as the fact that a document result was presented to a user, but was not clicked, postion(s) of click(s) in the user interface, IR scores of clicked results, IR scores of all results shown before the click, the titles and snippets shown to the user before the click, the user's cookie, cookie age, IP (Internet Protocol) address, user agent of the browser, etc. Moreover, similar information (e.g., IR scores, position, etc.) can be recorded for an entire session, or multiple sessions of a user, including potentially recording such information for every click that occurs both before and after a current click.
Google could have multiple buckets of click types, with one or more buckets in between long and short.
A short click can be considered indicative of a poor page and thus given a low weight (e.g., -0.1 per click), a medium click can be considered indicative of a potentially good page and thus given a slightly higher weight (e.g., 0.5 per click), a long click can be considered indicative of a good page and thus given a much higher weight (e.g., 1.0 per click), and a last click (where the user doesn't return to the main page) can be considered as likely indicative of a good page and thus given a fairly high weight (e.g., 0.9). note that the click weighting can also be adjusted based on previous click information. For example, if another click preceded the last click, the last click can be considered as less indicative of a good page and given only a moderate weight (e.g., 0.3 per click).
Each document's performance can be scored against the historical norms for that query.
the query categories can include “navigational” and “informational”, where a navigational query is one for which a specific target page or site is likely desired (e.g., a query such as “BMW”), and an informational query is one for which many possible pages are equally useful (e.g., a query such as “George Washington's Birthday”). Note that such categories may also be broken down into sub-categories as well, such as informational-quick and informational-slow: a person may only need a small amount of time on a page to gather the information they seek when the query is “George Washington's Birthday”, but that same user may need a good deal more time to assess a result when the query is “Hilbert transform tutorial”.
...
Traditional clustering techniques can also be used to identify the query categories. This can involve using generalized clustering algorithms to analyze historic queries based on features such as the broad nature of the query (e.g., informational or navigational), length of the query, and mean document staytime for the query. These types of features can be measured for historical queries, and the threshold(s) can be adjusted accordingly. For example, K means clustering can be performed on the average duration times for the observed queries, and the threshold(s) can be adjusted based on the resulting clusters.
One could use a service like BounceExchange (or a similar & cheaper alternative) to try to capture users who are about to leave, or they could perhaps use Javascript to disable the back button for some percent of users who have "Google" in the referrer string. Such strategies might in the short term increase the percent of search visits which are long clicks, but if users find them quite annoying then they might be less likely to intentionally click on your site again when conducting related searches in the future.
Another approach to improve the long click ratio would be to intentionally under-monetize the first click into your site, and then show more ads on subsequent pages. That ensures a clean user experience upfront & makes a good first impression, which in turn would perhaps make people more willing to click on your site when they find it in the search results on subsequent searches.
As your site becomes entrenched as a habit you can be more aggressive with monetizing.
Weighing Different Users Differently
Not only does the patent refer to keeping all that data on a per-query, per-document & per-session basis, but it also mentions tracking users to protect against click manipulation & throwing out the data when it appears a query has been intentionally manipulated.
safeguards against spammers (users who generate fraudulent clicks in an attempt to boost certain search results) can be taken to help ensure that the user selection data is meaningful, even when very little data is available for a given (rare) query. These safeguards can include employing a user model that describes how a user should behave over time, and if a user doesn't conform to this model, their click data can be disregarded. The safeguards can be designed to accomplish two main objectives: (1) ensure democracy in the votes (e.g., one single vote per cookie and/or IP for a given query-URL pair), and (2) entirely remove the information coming from cookies or IP addresses that do not look natural in their browsing behavior (e.g., abnormal distribution of click positions, click durations, clicks_per_minute/hour/day, etc.). Suspicious clicks can be removed, and the click signals for queries that appear to be spammed need not be used (e.g., queries for which the clicks feature a distribution of user agents, cookie ages, etc. that do not look normal).
And even amongst users which are not considered suspect for click spamming, Google can still weigh their click inputs variably based on a variety of factors.
User types can also be determined by analyzing click patterns. For example, computer savvy users often click faster than less experienced users, and thus users can be assigned different weighting functions based on their click behavior. These different weighting functions can even be fully user specific (a user group with one member). For example, the average click duration and/or click frequency for each individual user can be determined, and the threshold(s) for each individual user can be adjusted accordingly. Users can also be clustered into groups (e.g., using a K means clustering algorithm) based on various click behavior patterns.
Moreover, the weighting can be adjusted based on the determined type of the user both in terms of how click duration is translated into good clicks versus not-so-good clicks, and in terms of how much weight to give to the good clicks from a particular user group versus another user group. Some user's implicit feedback may be more valuable than other users due to the details of a user's review process. For example, a user that almost always clicks on the highest ranked result can have his good clicks assigned lower weights than a user who more often clicks results lower in the ranking first (since the second user is likely more discriminating in his assessment of what constitutes a good result). In addition, a user can be classified based on his or her query stream. Users that issue many queries on (or related to) a given topic T (e.g., queries related to law) can be presumed to have a high degree of expertise with respect to the given topic T, and their click data can be weighted accordingly for other queries by them on (or related to) the given topic T.
Another Google patent, Modifying search result ranking based on implicit user feedback and a model of presentation bias, discusses the idea of combining implicit user feedback while accounting for the impacts of presentation bias. The abstract reads:
The present disclosure includes systems and techniques relating to ranking search results of a search query. In general, the subject matter described in this specification can be embodied in a computer-implemented method that includes: receiving multiple features, including a first feature indicative of presentation bias that affects document result selection for search results presented in a user interface of a document search service; obtaining, based on the multiple features, information regarding document result selections for searches performed using the document search service; generating a prior model using the information, the prior model representing a background probability of document result selection given values of the multiple features; and outputting the prior model to a ranking engine for ranking of search results to reduce influence of the presentation bias.
If a search result has an extended snippet size or other features added to it, Google can account for that difference.
Google can normalize clickthrough rate data based on the type of the search, the length of the keyword, and how different listings are formatted. If a search query gets enough search volume they can use historical data as a baseline, and if it gets few searches they can look at things like the search category, related searches, query classification, the length of the search, & how listings with the same general listing enhancement type have performed.
User selections of search results (click data) can be tracked and transformed into a background probability of user selection in light of one or more presentation bias features, and this background probability can be used to adjust future search result rankings to reduce the influence of presentation bias on implicit user feedback. ... a prior model can be used to estimate what the implicit feedback should be for results that are too infrequent, or too recent to have sufficient historical records of implicit feedback applicable to them.
... The query categories can be identified by analyzing the IR scores or the historical implicit feedback provided by the click fractions.
And just like new keywords can be modeled for anticipated performance, so can new websites
If a result for a new search does not appear at all in the regular implicit user feedback model (e.g., the traditional click fraction is undefined for the result because the result has not yet been selected before) this result can be assigned a click fraction as predicted by this additional prior model for ranking purposes.
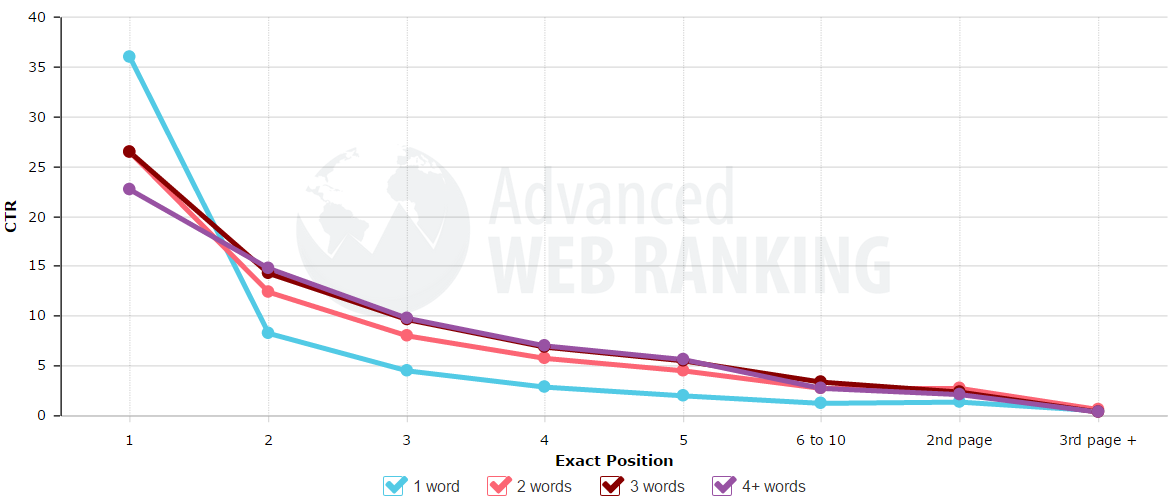
Earlier in this article I showed an AWR clickthrough rate curve which shows how branded keywords get many clicks on the top result, whereas unbranded informational searches get a more diverse clickthrough rate pattern, where users click lower into the result set. Other factors which impact CTR include things like: vertical search result insertion, ad insertion, sitelinks on ads or organic search results, and other listing enhancements like star ratings. Here is another AWR clickthrough rate curve which shows how as the number of ads on a search result increase, the CTR on the organic search results decreases.
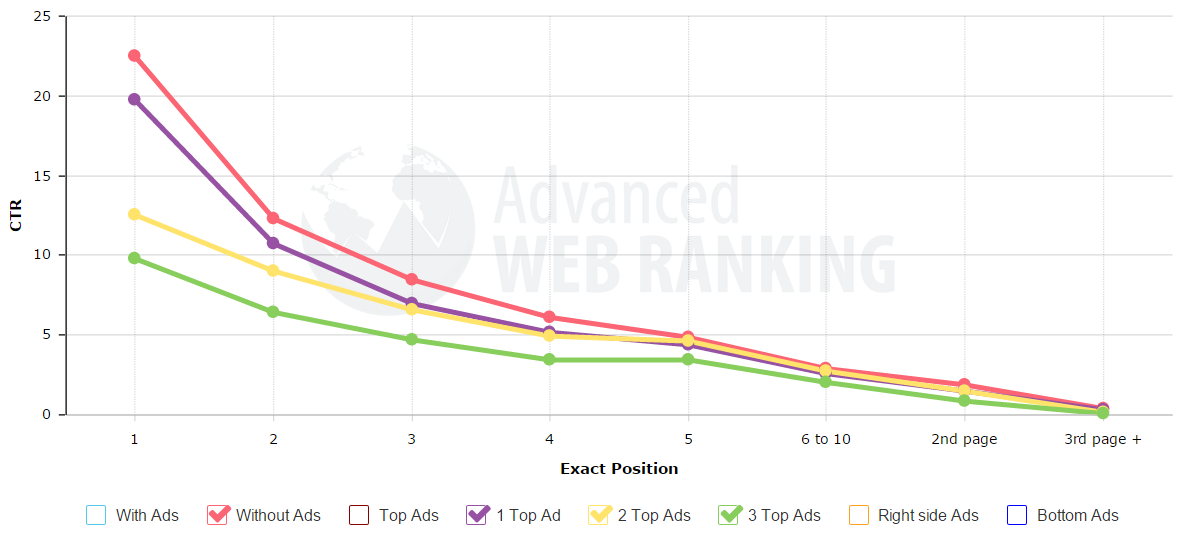
For any given search query Google can test various forms of result displacement & vertical search inclusion, and track the impact on user response. Google can then model that to predict how users may perform on other search queries. Such efforts allow Google to compare other ad formats against AdWords and optimize their layout for yield, while ensuring that users haven't started to abandon their search results due to excessive ad placement.
By mixing different ad types into the search result page Google is able to give the perception of result diversity while allowing ads to eat up a larger share of the search interface and a more significant percent of the overall click distribution.
What happened to organic results above the fold.. @Google pic.twitter.com/UkdBs1U42L— Dennis Goedegebuure (@TheNextCorner) July 9, 2015
I believe the story quoted below overstates the impact (especially in light of how many ads Yahoo! Search now shows in their interface), but you can be sure Google tests & tracks these factors.
The company was considering adding another sponsored link to its search results, and they were going to do a 30-day A/B test to see what the resulting change would be. ... Advertising revenues from those users who saw more ads doubled in the first 30 days. ... By the end of the second month, 80 percent of the people in the cohort that was being served an extra ad had started using search engines other than Google as their primary search engine.
A couple of the comments on that article expressed directionally similar results back when MSN Search was running Overture ads & tests with altering result quality with Bing. The Bing tests were mentioned in this paper. That paper mentions a book by Jim Manzi named Uncontrolled: The Surprising Payoff of Trial-and-Error for Business, Politics, and Society which stated "Google ran approximately 12,000 randomized experiments in 2009, with [only] about 10 percent of these leading to business changes." The paper also mentioned the importance of Bing looking at sessions per user and total users as primary metrics in their Overall Evaluation Criteria rather than revenue and query volume, because degrading organic search quality over the short run can lead to positive financial outcomes in the short term...
- an increased search marketshare by increasing the number of queries per session (as users are less satisfied with the result set)
- increased revenue per search (as the organic results look uglier, the ads get more clicks)
... which are also negative impacts over the long term (as those same issues eventually drive users away to competing services).
Weighing Different Search Queries Differently
Not only can Google trust data from some users more than others, but they can also choose to trust data from certain keywords more than others by partitioning user feedback. Google has a patent named Evaluating website properties by partitioning user feedback. The abstract reads:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for evaluating website properties by partitioning user feedback data are disclosed. In one aspect, a method includes receiving a plurality of document query pairs (D-Qs) associated with a website, partitioning the plurality of D-Qs into one or more groups according to values for a partition parameter associated with the plurality of D-Qs, evaluating a property parameter of the website based on aggregated user feedback data of the D-Qs included within at least one of the one or more groups, and providing the evaluated property parameter as an input for ranking documents from the website as result documents for searches.
Here are a couple images which convey the concepts in the patent.
A model for a page (or a group of pages in a site) can be made through the query,document pairs it ranks for.
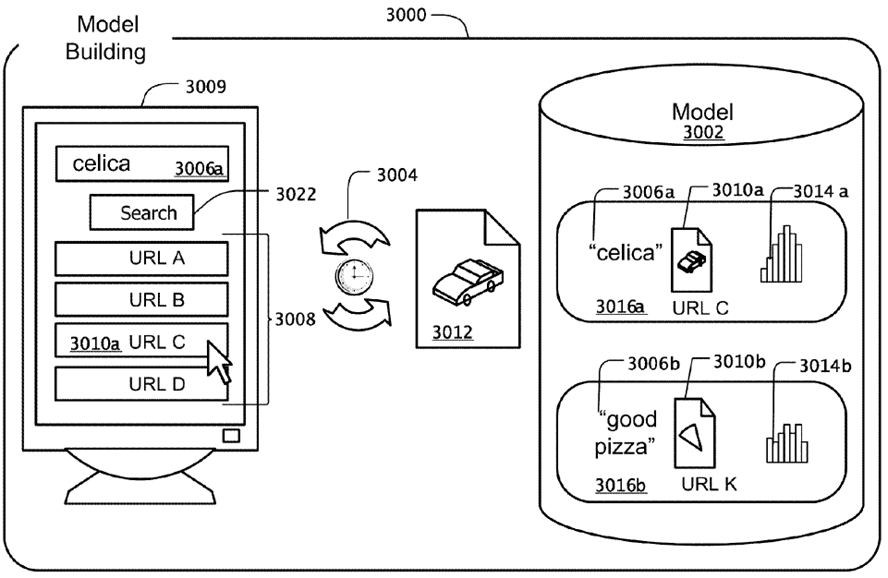
From that, Google can evaluate the types of keywords the site ranks for & users engage with it on, and partition those engagements into different buckets. Is this site mostly ranking for lower quality search queries? Is this site mostly ranking for higher quality search queries?
Google can determine the quality of the search results by looking at the information retrieval score of the top ranked page in the result set for that search term.
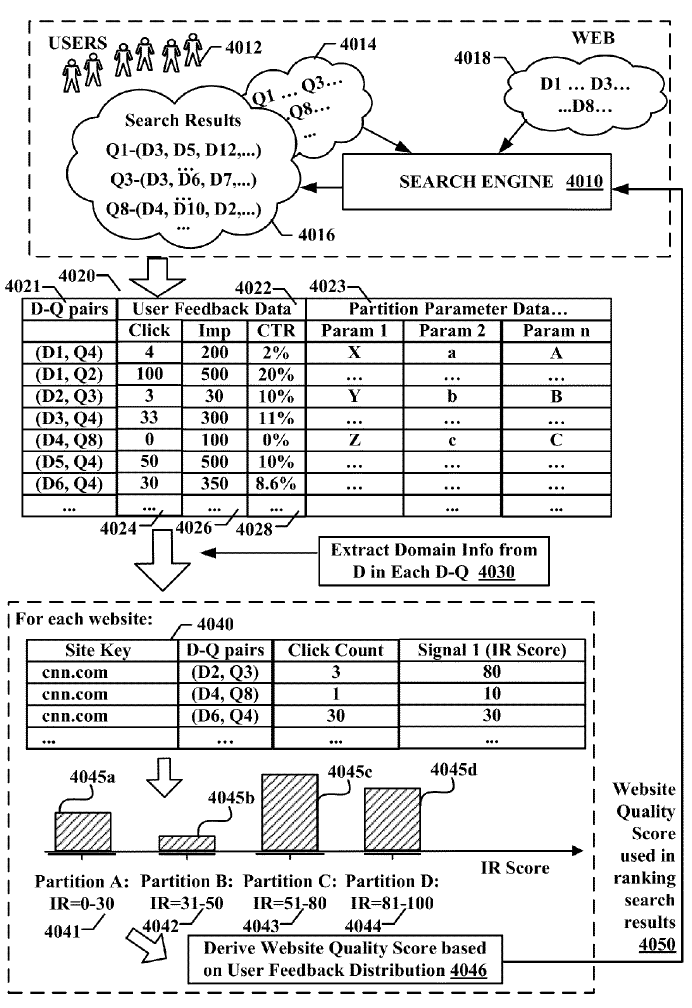
Through analyzing the partitioned buckets, Google can then create an aggregate website quality score.
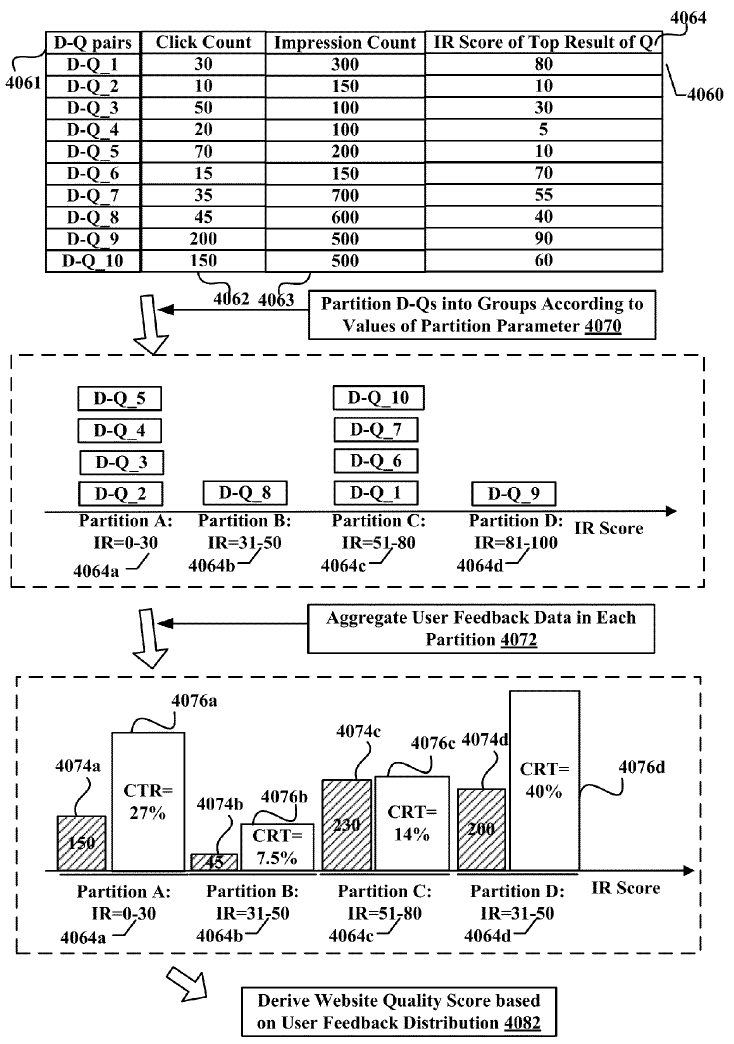
At first the patent comes across as sounding like many of the other user feedback related patents, but where this patent is different is partitioning the user feedback and comparing the skew of different sites.
A site which mostly ranks for longtail queries, misspellings, and stuff like that might be presumed to have limited quality, based on that ranking footprint. Whereas sites which rank for more competitive, higher search volume & commercially oriented queries and have good user engagement metrics on those can be presumed to be a high quality website.
Google can compare the skew of the overall ranking footprint of a site (ranking mostly for crappy terms, ranking mostly for good stuff, etc.) by the information retrieval scores of the top ranked sites in the result sets it ranks for.
Here are some quotes from the patent
In some implementations, each user feedback data includes one or more of a click-count, an impression count, and a click-to-impression ratio.
In some implementations, the click-count is weighted by click-duration or click-recency.
In some implementations, the partition parameter associated with each D-Q is an information retrieval score of a top-ranked document responsive to the respective query of the D-Q.
In some implementations, the partition parameter associated with each D-Q is a length of the respective query of the D-Q.
In some implementations, the partition parameter associated with each D-Q is a measure of popularity of the respective query of the D-Q.
In some implementations, the partition parameter associated with each D-Q is a measure of commerciality of the respective query of the D-Q.
In some implementations, the partition parameter associated with each D-Q is a total number of search results responsive for the respective query of the D-Q.
In some implementations, evaluating the property parameter of the website further includes the actions of: aggregating the respective user feedback data associated with the D-Qs in each of the one or more groups; determining a distribution of aggregated user feedback data among the one or more groups; and evaluating the property parameter based on the distribution.
If Google knows users tend to like a specific document when searching for a particular keyword, then they can fold that data back into the ranking algorithms. But if a particular document is new & does not yet have a strong ranking footprint and user engagement profile, Google can leverage the data from other documents from the same site:
statistical analysis of the aggregation of user feedback data can be performed at a website level, and the website property parameter can be used as an input in ranking individual documents from the website as search results for queries. Therefore, even if user feedback data for a particular document from the website is lacking, the user feedback data for other documents from the website can be utilized to improve the ranking accuracy of the particular document in searches.
For each query they can look at a variety of "footprints" associated with keyword for clues to its value
The various signals associated with a document-query pair are indicative of various properties of the document, the query, or the document-query pair. For example, a signal defined by the IR score of the top result document of a query is indicative of the quality of the query. A signal defined by the submission frequency or total submission volume of a query is indicative of the popularity of the query. A signal defined by the total number of advertisements targeting the search terms of a query is indicative of the commerciality of the query. A signal defined by the total number of advertisements presented on a document is indicative of the commerciality of the document. A signal defined by the total number of queries to which a document is responsive indicates the breath of the topic coverage of the document. A signal defined by the total number of result documents responsive to a query is indicative of the competitiveness of each document responsive to the query. A signal defined by the IR score of the document as a search result to a query is indicative of the relevance of the document in the context of the query.
And really the meat of the patent is in the following section:
In order to determine whether a particular website is of high quality in terms of producing relevant, accurate, and/or popular search results, one or more suitable partition parameters (e.g., Param 1, Param 2, etc.) are selected and used to segregate the set of D-Qs associated with the particular website. One suitable partition parameter is the IR score of the top result for a query across all websites. The rationale for selecting such a partition parameter is that, if the IR score of the top result for a query across all websites is high, it is more likely than not that the query is a well-formulated query, and that the user feedback data for documents responsive to the query are more likely to reflect the quality of the documents and the quality of the websites containing the documents. On the other hand, if the IR score of the top result for a query across all websites is low, it is more likely than not that the query is ill-formed or related to an obscure topic, and the user feedback data for documents responsive to the query are less likely to accurately reflect the quality of the documents and the quality of the websites containing the documents. Therefore, by using this signal to segregate the user feedback data associated with a particular website, a high concentration of positive user feedback (e.g., as reflected by a high click-through rate or a large number of click-throughs) in the high IR score range indicates high website quality, while a high concentration of positive user feedback in the low IR score range does not indicate high website quality.
They highlight, as an example, CNN ranks well for high-quality queries
as shown in FIG. 4A, the aggregated click counts (4045 a-d) for the website “cnn.com” are mostly concentrated in the high IR ranges 51-80 and 81-100. This concentration of aggregated click counts in the high IR ranges tends to indicate that the website is of high quality. In some implementations, an aggregated click-through rate is computed for each partition as well. A combination of both high click-through rate and high click-count in the high IR ranges provide even stronger indication that the website is of high quality.
A shorter typical query length of 2 or 3 words can also be a signal of higher quality
In some implementations, the website quality score is derived based on a combination of multiple distributions of aggregated user feedback data, where each distribution of aggregated user feedback data is obtained according to a different partition parameter. For example, in addition to the IR score of the top result document of the query, another partition parameter relevant to website quality is query length (e.g., the number of terms in a search query). Queries that are neither too short nor too long tend to produce results that are good matches to the query (i.e., neither too general nor too specific). Therefore, if the clicks for documents on a website concentrate in the partitions that are associated with the high IR ranges, and in the partitions that are associated with queries having only two or three words, then it is highly likely that the website is of high quality.
Of course both of the above quotes are just another form of implementing brand bias. Big news sites or big ecommerce sites which are allowed to rank quickly for new terms without needing link building are quick to build user engagement feedback data on those search terms. Smaller sites which must focus on less competitive and more obscure terms can then be stuck in those niches UNLESS they can generate enough brand awareness to fold back into the algorithms and allow them to rank better for the more competitive and higher quality keyword terms.
In some implementations, the distributions of aggregated user feedback data among different partitions made according to one or more partition parameters are used to filter out websites of poor quality. Threshold values of the aggregated user feedback data can be specified for certain partitions of interest. For example, if, for a website, the aggregated click count for the high IR score partition is below a click count threshold and the aggregated click through rate for the high IR score partition is also below a click-through rate threshold, then the website is considered of poor quality. A website quality score can be computed for the website. When ranking a document from the website as a search result responsive to a search query, the rank of the document is demoted based on the poor quality score of the website.
Longtail queries may not have enough matching results to deliver high quality results. Single word queries may not be given much weight due to limited discrimination value:
Typically, if a search query includes a single term, many results will be returned, and many of the search results are likely to be irrelevant for what the user actually intends to search for because there is too much room for ambiguity in a single search term. Alternatively, if a search query includes a large number of search terms, very specific results will be returned regardless of the quality and general applicability of the website serving the result documents. Positive user feedback for result documents of queries that are of medium length (e.g., two or three words) are indications that the result documents are of good quality. Therefore, a high aggregated click count in partitions defined by a medium query length (e.g., two or three terms) likely indicates good website quality.
And just like they can look at the number of words in the search query and the IR score of the top ranked search result, they can also look at the total number of search results for a search query & the popularity of the search term.
The total number of search results responsive for a query is indicative of how much significance positive user feedback toward a particular result document should be given in determining the quality of a website serving the particular result document. If many results were returned for a search query, then the positive feedback for a result document from a website is a stronger indicator of relevance and quality for the document and the website than if only a small number of results were returned for the search query.
...
if the total number of submissions for the search query “bankruptcy” is 3000 per day, and the total number of submissions for the search query “arachnids” is 50 per day, then the query “arachnids” is a less popular query than the query “bankruptcy.” The measure of query popularity is relevant in determining website popularity because websites serving well-received documents responsive to popular queries are likely to be popular websites.
Commercial terms can also get extra weighting, since many people are competing on those terms, investing heavily in relevancy and user experience:
Knowing the level of commerciality of a website helps ranking search result in a product search, for example. Alternatively, highly commercial website is also likely to be a spammed website with lots of advertising but little relevant information. A suitable partition parameter for deriving the commerciality score of a website is defined by the number of advertisements presented on the webpage. Alternatively, a suitable partition parameter may be defined by the number of advertisements targeting the search terms in a search query. Positive feedback for highly commercial documents or documents responsive to highly commercial queries likely indicates that the website serving the documents are highly commercial as well. A highly commercial website may be promoted in a product search, but may be demoted in a search for non-commercial information.
Consider the following keyword examples
| Search terms | monthly searches | Competition | Suggested bid | Ads | Keyword value | Discrimination Value | Words | Matching Documents | Query IR Score |
|---|---|---|---|---|---|---|---|---|---|
| the | 368,000 | Low | $4.77 | 0 | $0.00 | ~0 | 1 | 25,270,000,000 | super low |
| trees | 90,500 | Low | $0.97 | 0 | $0.00 | slight | 1 | 738,000,000 | low |
| bonsai tree | 74,000 | High | $0.63 | 12 | $46,620.00 | good | 2 | 1,450,000 | ok |
| bonsai trees | 6,600 | High | $0.75 | 13 | $4,950.00 | good | 2 | 1,180,000 | ok |
| buy bonsai tree | 720 | High | $0.64 | 15 | $460.80 | high | 3 | 1,250,000 | good |
| bonsai tree amazon | 210 | High | $0.44 | 1 | $92.40 | extremely high | 3 | 411,000 | great |
| small tree from japan as a houseplant | – | – | – | 0 | $0.00 | decent | 7 | 430,000 | low |
A query like "the" might have some powerful sites ranking for it, but since "the" is such a common term it has little discrimination value or meaning. That is one of the reasons the word "the" is called a stop word - by itself it means very little because it is so common. Thus the click distribution for anyone searching for that query might be quite random or astray, and a lot of people who search for that might not click on anything & then refine their query before clicking on something. While the suggested bid in AdWords is high on this term, it is not high because the term has value, but rather because Google has seen the ad performance was terrible in the past and is making the cost prohibitively high to prevent advertisers from running dictionary attack spam ad campaigns against them. This is why there are no ads on this keyword.
"Trees" has more discrimination value than "the" but it is still such a broad query that it is hard to match user intent on. Does someone want to know about:
- how long trees have existed for
- the types of trees which exist
- what the biggest and smallest trees are
- types of trees to have as houseplants
- how trees make energy
- how trees interact with people
- how to donate to have more trees planted
- buying a calendar with trees on it
- seeing photos of trees
- buying a houseplant
- etc.
The intent is hard to match up. And while ArborDay.org is a great site to show for that broad/general query, the query wouldn't have a high IR score because most people would likely refine the query further & those clicking on the search results might click on a diverse set of them. Again, the lack of search ads and high suggested bid (in spite of low suggested competition) is more of a tax for irrelevancy than an signal of commercial intent.
The term "bonsai tree" has much more discrimination value and is specific enough that Google allows ads to run on the search results, and thus their suggested bid prices is more reflective of actual commercial value. Some people might want to know their origin, how to grow them, or how to buy them, so there is a number of intents, but would still likely click decently high on the search results.
When someone types in "buy bonsai tree" they are expressing a clear & singular commercial intent. There might be a couple potential minor deviations (say residential orders versus large commercial orders) but for the most part the query intent is quite consistent among most users and that would lead to most people clicking on one of the top few search results & the query having a fairly decent information retrieval score.
When someone from the United States types in "bonsai tree amazon" they are expressing an even stronger intent. They would like to research or buy bonsai trees available on Amazon.com. This query would have an exceptionally high information retrieval score, as most people searching for that will click into Amazon.com.
A search query like "small tree from japan as a houseplant" still has perhaps an ok discrimination value, but it doesn't use the high discrimination value term "bonsai" in it. And because it is such a long search query (7 words) there are so few people searching for it that it doesn't make sense to put much (or perhaps any?) weight on usage data tied to this search query. What's more, since the query is so long, for Google to have many matching documents they likely had to conceptually transform some of the terms on the backend (e.g. small tree from japan = bonsai) to get many matches in the organic search results. So the IR score on this sort of query wouldn't be great.
When Google rolled out Google Instant to auto-complete search queries, the net effect was to segment demand in a way that drives users down well-worn paths. It made it easier for them to make spelling corrections on the fly and consolidate search volume onto fewer terms, which in turn made it easier for Google to match ads against the search queries and it also allowed Google to promote search queries where they already had greater confidence in the quality of their search results.
Another thing worth pointing out with the above concept of keyword value (search volume * suggested price * are there ads shown) is the the numbers there are a good directional proxy for the resources Google can justify spending on having remote quality raters regularly police/rate/review the associated search results. So with valuable and popular search queries Google not only has more usage data to monitor and create signals from, but they also have more resources to spend on verification of result quality with their remote quality raters.
In the past a Google engineer stated Google didn't care much about the impact on porn-related search terms when doing algorithm updates. Porn queries are exceptionally popular, but since Google doesn't monetize them & they are toward the sketchier end of the spectrum, they don't care much about the quality of those results. They are willing to let someone else have that market. To appreciate how little Google cares about those results, consider the following excerpt from Ken Auletta's Googled: The End of the World As We Know It:
When [Matt Cutts] joined the company in 1999, among his first tasks was to figure out how to block pornography searches, which accounted for one in every four queries. His solution was to assign a lesser weight in the Google algorithm to words commonly used in porn searches, or for Google's engineers to misspell the keywords in the Google index so the porn was difficult to retreive. First he had to figure out the pertinent words. He spent hours pouring over porn documents. Then his wife came up with the idea of baking cookies and awarding one "porn cookie" to each engineer who discovered a salacious keyword. Porn search traffic plummeted.
In summary, from the above patent...
if the distribution of the aggregated user feedback data is skewed toward the high IR score ranges, the distribution indicates that the website is of good quality. In contrast, if the distribution is screwed to the low IR ranges, then it indicates that the website is of poor quality.
In some implementations, combinations of multiple distributions based on different partition parameters are used to improve the accuracy of the website property evaluation. For example, if the aggregated user feedback data is skewed toward the high IR scores, and the aggregated user feedback data is skewed toward highly competitive queries, then it is highly likely that the website is of good quality. The prediction of good quality is stronger than if the aggregated user feedback is skewed toward high IR scores while the aggregated user feedback is also skewed toward uncompetitive queries.
...
User feedback distributions for websites of different properties and attributes are compared to derive distribution characteristics that are indicative of the different properties. The derived distribution characteristics are then used to predict the properties of other websites.
(Countering) the Rich Get Richer Effect
One of the issues with using the link graph as a primary ranking signal is there is a "rich get richer" effect, where sites which have ranked for a long time keep accruing additional inbound links by virtue of the exposure earned by ranking well. To some degree using end-user usage data suffers from this same problem, as documents which rank well have lots of relevant usage data to weigh and documents which do not yet rank well don't have much data to weigh in.
There are a number of ways Google can compensate for that bias.
- estimate performance: given the signals associated with a document (the performance of other pages on the same site, the performance of other documents with similar textual footprints, etc.) Google can attempt to estimate how they might believe a document would perform & use that estimate as a signal until they gain more concrete usage data statistics.
- showcase: Pages can be tested at various rankings for a short duration of time and user engagement metrics sampled to collect performance data.
- weighing recency and historical trends:
- On popular search queries with lots of user click data, older click data can be discounted since it is stale & less relevant to current market conditions.
- Trends in recent user selection data can be used in order to track if a particular document is gaining clicks faster than the general trend for the associated search queries. If a document is getting more clicks than would be anticipated based on its rank position & the ratio of overall click volume it is attracting is going up, then the document can get a ranking boost.
- The combination of these two temporal weightings (along with other factors like QDF) ensures that as searcher intent changes with queries the newer data is quickly folded in and stale data doesn't inhibit the ability of a search engine to respond to shifts in consumer interests. And by de-weighting older data only on more popular search queries, it ensures search engines do not discard useful engagement data on rarer search queries. Further, if a new document offers new layers of value and becomes a compelling habit, then users who view it will be more likely to re-select it again in the near future, ensuring that over time it keeps getting a disproportionately large share of the most recent click volume.
The estimated performance concept was referenced in some other patents mentioned in this article, and the temporal weighing of user feedback data was referenced in a recently approved Google patent named Modifying search result ranking based on a temporal element of user feedback.
Filtering Out Fake Users & Fake Usage Data
Google released a feature which shows all the locations a user has ever visited if they have opted into Google's location history feature. They are keeping that granular of data in their database on a per-user basis. They have a local beacon platform for developers and show localized business foot traffic by time of day, which would be easy for them to turn into a relevancy signal - just like driving direction lookups.
In the above section there was a subheader for weighing different users differently & deciding when to discard data based on a user not fitting a normal user profile, or when a keyword seems to have usage profiles that are far outside the norm. Google has a patent on Detecting Click Spam. Here is the abstract from that patent:
A computer-implemented method for processing network activities is described. The method includes identifying a model that specifies attributes for network objects, identifying a network object having one or more attributes that deviate from the model, and providing as an input to a ranking algorithm a value associated with the deviance of the one or more attributes of the identified network object.
The following image shows an example of how they could grade different IP addresses.
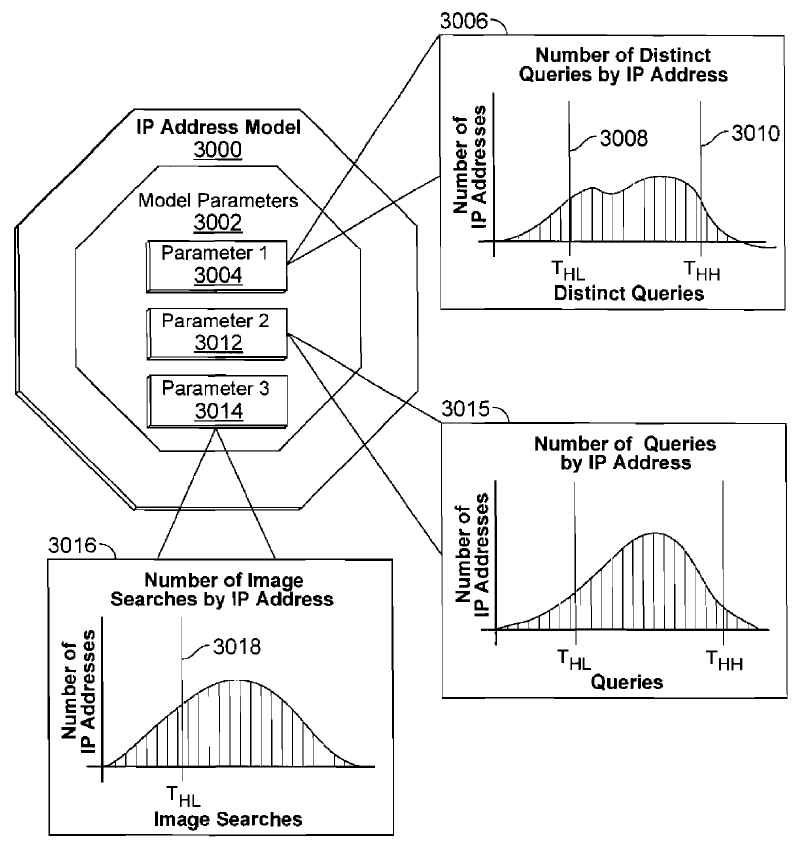
The above image shows a couple examples of things they could look at like the ratio of image searches to regular web searches, their total search volume, and the number of distinct search queries they perform. There are many other heuristics Google could track, like: IP addresses tied to a user cookie, length of user account history, usage history of YouTube, if the person has a credit card on file, location from their IP address versus how they search, clickthrough rates on the search results / click-to-query ratio, short clicks versus long clicks from search, if many of their search clicks are on results from page 2 or beyond, etc.
First, some implementations can improve the ranking of search results based on network behavior, such as hyperlink selections, by filtering out anomalous network behaviors. Second, certain implementations make it difficult to spam a significant portion of click data used to modify the ranking of search results by implementing techniques that require significant time and resource investments to circumvent. Third, some implementations can increase the detection of click spam by generating several independent layers of spam filtering criteria. Fourth, certain implementations can dynamically update models used to detect deviant network activity.
A profile which has maybe 1 or 2 deviant or abnormal aspects can still count just fine, but if it has many deviant attributes it can be aggressively or completely discounted.
click spam filtering includes multiple layers of independent safeguards, which can include: removing clicks, or selections, associated with new or invalid cookies; limiting a number of clicks based on a particular search query that a single cookie or internet protocol (IP) address can submit during a time period (e.g., one hour, one day, etc.); extracting statistics for individual cookies or IP addresses and filtering out clicks from the cookies or IP address that have anomalous behaviors or attributes; limiting a number of “votes” that a cookie or IP address can contribute to a given query/result pair for algorithms that infer relevance of documents based on the votes; and computing click statistics on a query basis to determine if the clicks appear plausible.
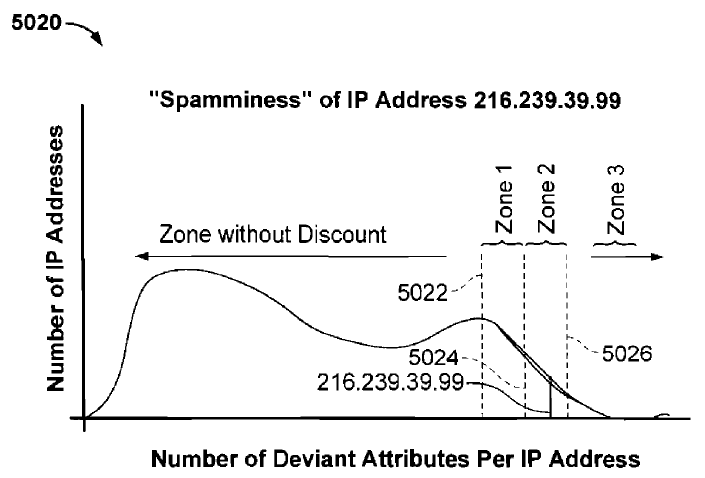
The above spamminess heuristics are not only collected on a per-user or per-IP address basis, but also in aggregate on a per-query basis:
In certain implementations, statistics are collected based on queries. For example, query-based statistics can be gathered for each query and may include: a number of cookies that submitted the query, a number of IP addresses that issued the query; how many times a click was submitted from a malformed cookie for the query (e.g., a malformed cookie may not conform to the correct cookie format specified by the issuer or it may not have a valid digital signature); how many times a click was submitted from a “bad” cookie for the query (where a cookie can be classified as “bad” if it deviated beyond a threshold when compared to a model of a typical cookie); a distribution of “spam scores” for cookies that clicked based on the query (where a “spam score” indicates a deviance of a network object from a model of the expected behavior or attributes of the network object); and a distribution of a spam score for IP addresses that clicked based on the query.
Additional query-based statistics collected for each query can include: a ratio of a number of clicks relative to a number of times the query was issued; a distribution of clicks by URI; a distribution of clicks by position (e.g., position on a web page or ranking on a web page); a distribution of clicks by cookie; a distribution of clicks by IP address; a distribution of click lengths; a distribution of ages of cookies that clicked on a result for the query; a distribution of ages of the cookies that submitted the query; a fraction of clicks on advertisements relative to all clicks; a fraction of users that issued the query and have a particular web browser toolbar; a distribution of clicks for the query by client device (e.g., web browser or operating systems); a distribution of clicks by language of the user (e.g., which may be explicitly provided by the user or inferred from the user's location or search history); a distribution of user languages that issued the query; a ratio of clicks resulting from the query relative to a global average of clicks from other queries for a particular user; and a distribution of clicks by user location (e.g., country, region, or city), which may be explicitly provided by the user or inferred, for example, from a user's IP address or search history.
...
The statistics based on queries can be used to identify clicks that should be classified as anomalous. For example, if a particular query deviates from a model describing the expected attributes for a typical query, clicks that result from that query (e.g., selections of search results based on the query) can be classified as deviant, too.
Those user-based or query-based statistics can also be applied to selected URLs ranking within the SERPs
In certain implementations, statistics that are similar to the query-based statistics can also be computed for each URI or web domain. This can also be used as an indication of the spamminess of a model.
And through that sort of lens, Google could easily detect many of the cheapest and fastest ways to generate branded search volume in bulk as being anomalous by nixing cookies with incorrect digital signatures and discounting data associated with sites or queries which have most of their search volume from newly issued cookies. Google could also choose to place less weight on usage data from countries where there is lots of spammy data. For example Yandex mentioned removing links from their ranking algorithms in some markets & that of course led to much more sophisticated usage data signal spoofing within Russia. Yandex restored links as a ranking factor a year later.
And, while everything is being tracked, huge spikes in query volumes for a keyword or click data for a result can flag them for either algorithmic filtering of that data or a manual review process.
Google relies heavily on user click data to drive ad relevancy (see 5 minutes into this video or this white paper). Years ago at an Affiliate Summit, Google's Frederick Vallaeys mentioned that was one of the ways Google detects policy violations in AdWords. When some competitors get removed from the ad auction, remaining competitors in the same space get a spike of impressions and clicks. If that category is one Google is clamping down on at the time then it is quite easy for Google to mow through a category quickly because as they remove violations the remaining gray area players get more volume, get flagged for review, and then get hit if they are on the wrong side of the policy.
It is easy for a celebrity to create news as desperate news publishers chase anything that draws lowest common denominator pageviews. But outside of that sort of activity, it may be hard to massively spoof click data at scale without leaving footprints. That said, click manipulation efforts *can* work (at least temporarily).
Each day Google has more data & more computing power to sort through the data. While Google may use machine learning more aggressively for a broader range of tasks, they still have human biases in aspects of their relevancy process. Those biases help determine: when it makes sense to override any "errors" or false positives, and what signals to rely on to override them.
"When I was on the search team at Google (2008-2010), many of the groups in search were moving away from machine learning systems to the rules-based systems. That is to say that Google Search used to use more machine learning, and then went the other direction because the team realized they could make faster improvements to search quality with a rules based system. It's not just a bias, it's something that many sub-teams of search tried out and preferred.
I was the PM for Images, Video, and Local Universal - 3 teams that focus on including the best results when they are images, videos, or places. For each of those teams I could easily understand and remember how the rules worked. I would frequently look at random searches and their results and think "Did we include the right Images for this search? If not, how could we have done better?". And when we asked that question, we were usually able to think of signals that would have helped - try it yourself. The reasons why *you* think we should have shown a certain image are usually things that Google can actually figure out." - Jackie Bavaro
The biases which are inside the heads of the search engineers get expressed in how they write the relevancy algorithms and what signals they choose to use. They then get expressed once more in the remote rater guidelines, when then get reflected back into the ratings from remote quality raters.
Recently Rand Fishkin asked people to search-n-click on Twitter, and quickly saw the search results change.
If you're curious - results came in rather quickly. Will be interesting to see how long it lasts. pic.twitter.com/I9mJLj2GMq— Rand Fishkin (@randfish) June 21, 2015
Then those results quickly changed back.
The cynical view on why the results quickly changed back would be a Google engineer saw the Twitter stream and decided to undo the metrics. But the Google patent on detecting click spam mentioned looking for outliers in usage data to automatically discount using clickstream data for the associated queries.
Darren Shaw tested providing implicit user feedback by clicking on results using services like Amazon Mechanical Turk, but he wasn't blogging about them or sharing them on Twitter. His tests proved inconclusive. The stuff he pushed on really hard in a short burst didn't have a sustainable impact, but the stuff which was done more slowly seemed to work better. I would recommend downloading and reading through his slides to get a feel for what worked for him versus what didn't.
Darren Shaw - User Behavior and Local Search - Dallas State of Search 2014 from Darren Shaw
Bartosz Góralewicz tested creating a click bot which he programmed to click on every site but his & he saw his rankings tank within a month:
I created a bot to search for “penguin 3.0” and click on a random website. There is only one exception: it was programmed not to click on https://goralewicz.co, thereby massively lowering my Click Through Rate.
I sent a load of traffic to this keyword from all around the world, clicking everything except my website.
My Penguin 3.0 page quickly plummeted.
He didn't share how he coded his clickbot, how often it was clearing cookies, what browsers it used, or how he was searching from many places around the world. That said, the ease with which he performed it certainly made it sound as though these searches were not from logged in user accounts. What's more, there are some seriously widespread networks like Hola.org which are easily accessible to marketers through services like Luminati.io.
And, at the broader level, people have tested using services like Mechanical Turk for over a half decade. Some ads for sites like CrowdSearch.me even promote a "search manipulation in a box" service. CrowdSearch.me was created by Dan Anton, the same guy behind BacklinksVault. Here's their banner
Here's their YouTube hosted intro video
They've been promoted many times on WarriorForum and had thousands of sales.
(I am not recommending them, only stating how widespread this stuff is becoming. There are also sites like PandaBot.net with a similar marketing approach. How much of the protections mentioned in the patents are applied is likely determined largely by how much of an outlier the usage data is for a specific site. More aggressive & less variation = lower odds of working. Faster & cheaper to implement, marketed heavily via hyped up marketing = lower odds of working. The nice thing about any of these services is it wouldn't be hard to test them on a page on a large site like Amazon or eBay before testing anything on a much smaller niche site.)
Spoofing Google-Only Relevancy Signals vs a Broader Approach
I won't recommend any specific type of signal spoofing, in part because if I recommended something and it became popular then Google could move to quickly make that method / source / strategy ineffective. In general though...
- The patents try to make it sound like it is easy to neutralize all search engagement-related manipulation efforts. But earlier patents also made it sound like it was easy to neutralize all link manipulation efforts, and yet people were able to succeed with links-only SEO about a decade after the patents made it sound like the opportunity had already disappeared. Some succeeded longer than others with the link manipulation efforts.
- If you aim to manipulate signals (through the use of Amazon Mechanical Turk, click bots, or any other strategy), then the more other things you are doing in parallel to the manipulation efforts the less likely the manipulation efforts are to stick out as an outlier to ignore.
- If you push really hard in a short burst it is more likely to be detected as unnatural and discounted. Whereas if you do something which is slower and more sustained it is less likely to get flagged as an outlier. And if you build the signals through a variety of parallel search queries that is less likely to stick out as an outlier than if you were to try to hit a single keyword aggressively.
- If people are interacting with you and seeking out your site, they are going to leave some signals which Google can fold into their relevancy algorithms, even if many of those signals are created indirectly.
Sugarrae wrote a guide to how she had SEO success in Google without link building by primarily marketing a site on Pinterest. In the community TimMcG mentioned seeing a significant and sustained Google lift after a site went viral on Pinterest and Facebook.
Sampling User Internet Traffic
Google has an older patent on sampling internet user traffic to improve search results. The abstract reads
Methods, systems and apparatus for improving Internet search results include monitoring network activity on a communications network, generating a near real-time map of the network activity, and integrating the near real-time map with a search engine.
In the patent they reference getting data from ISPs and proxy servers, however this patent was filed before they had a broad install base on Android and the Chrome web browser. Google could easily tap these same sort of data signals using the combination of...
- Chrome
- Android
- Google Fiber
- Google Fi
...and security features baked into these sources.
In the patent Google highlighted the drawbacks of the links-and-keyword based ranking system.
Regardless of the particular method used to rank web pages in response to a user's query, this approach to search engine design has several significant drawbacks. First, the ranking algorithms are biased toward older pages because there are usually more links pointing to an older page than there are links pointing from the older page. Second, the ranking method is self-reinforcing because pages that are highly ranked will be linked to by more users, which will increase the ranking. This “all roads lead to Rome” phenomenon can continue even after the web page is inactivated (becomes a dead page), because the sheer size of the web prevents any search engine with a single point of view (i.e., the search engines web crawler) to cover the entire web in a short period of time. Third, user navigation to web pages without the use of hyperlinks (e.g., by entering a URL directly into a web browser) is not part of the search engine ranking calculus.
The benefit of leveraging end user data directly are allowing Google to
- more quickly compensate for changes in consumer behaviors
- fold in direct navigation (typing a URL in a browser address box) as a ranking signal
- cluster popular related breaking news articles together as important and associate them with a topic
- quickly remove dead nodes from their search results.
It also makes it easy for them to cluster related search queries based on people who type different queries selecting the same destination. And it also mentions using search queries to model personalized user behavior & personalize the search results to other searchers who have some of the same browsing behaviors:
Activity may be tracked by geographic location, by the number of similar websites visited during the monitoring period, by the number of similar queries submitted during the monitoring period, or any other metric that may be available from web data.
Four years ago Google conducted a sting operation on Bing after Bing was using Google search query data as a relevancy signal. At the same time Google was scraping product sales and review information from Amazon. And Google's above patent on monitoring web traffic included the very thing Bing was doing:
In one embodiment, the web graph is used to improve search results in one search engine based on the search results in another search engine. The search engine will return search results to the user, and the user may pick one of the search results and navigate to the selected web object. All of the user activity (e.g., including query and the pick) may be logged in activity log and used by web traffic monitor to update web graph. For example, the query and the selected object from the search engine may be associated with each other.
Bing's BrowseRank
Back in 2008 Microsoft also published a BrowseRank research paper which highlighted using browser data to boost search relevancy. Here are a couple graphics from the paper.
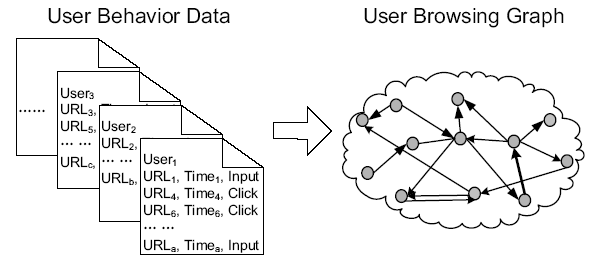
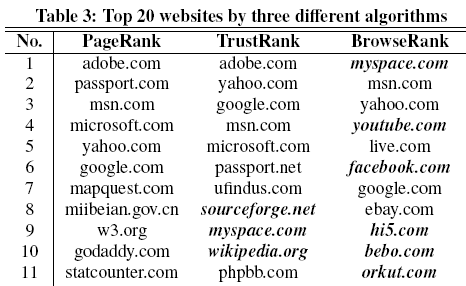
Localizing Search Results
Google has long personalized search by ranking sites you have recently or frequently visited higher in the search results. The also sometimes append words from a prior search query when you conduct subsequent searches. Usage data is also leveraged for spelling correction and localizing search suggestions down to the city level based on searches other people near you have done.
Google has patents on Refining Search Results and Modifying Search Results Based on Populations. Here are some highlights from those patents.
From Refining Search Results...
Users can be modeled based on how they align with prior searchers...
By defining particular user characteristics (e.g., user languages, user locations, etc.) as being compatible, information associated with previous searches may be exploited to accentuate or downplay the rankings of search results.
...based on that alignment, Google can choose how much weight to put on different granular buckets of prior search data
In one arrangement the rank modifier engine 1056 may modify rankings based on one of three distinct levels. At the first level, the rank modifier engine 1056 may rely upon information from similar queries previously initiated by search requesters using the same language and from the same general location (e.g., country) as the current search requester. If such information is lacking, the rank modifier 1056 may attempt to modify rankings at a second level. In one arrangement, the second level may allow additional information from previous searches to be used. For example, the second level may use information from similar queries previously initiated by search requesters that use the same language as the current search requester, but independent of the location of the previous search requesters. As such, additional useful information may become available by expanding the pool of previous search information. If a statistically significant amount of information is still absent, the rank modifier engine 1056 may further expand the pool to include data from all previous searches that were similar to the current search. As such, search information independent of search requester language and location may be used.
Google may also choose to weigh data from parallel languages which share some similarities
similarities associated with user languages (e.g., Russian and Ukrainian) may be used for ranking search results. By recognizing the similarities in particular languages, information associated from previous searches for both languages may be exploited. For example, the rank modifier 1056 may be unable to identify previous search requests provided in Russian that are similar to a current Russian search request. As such, the rank modifier 1056 may elect to open the search pool to include previous searches independent of language. As such, some previous search requests in Ukrainian, which is similar to Russian, may be applied a similar weight (even if highly relevant) to another language (e.g., Chinese) that is very different from Russian, but for which a significant amount of search requests may exist. By taking language similarities into account, the rank refiner engine 1058 may allow previous search information to be exploited, which may provide more relevant result rankings for the search requester.
Likewise, where countries neighbor, Google can leverage data from the neighboring country on the presumption that some portion of the population from one country migrated to another.
similarities associated with searcher locations (e.g., country of the searcher) may be considered. In one some arrangements, similar geographical locations (e.g., bordering countries such as Mexico, Canada, the United States, etc.), locations with common culture and climate (e.g., northern African countries), or other types of similarities may be used for adjusting the rankings of search results. Further, such language and location similarities may be used to define additional levels that may be inserted between somewhat abrupt levels (e.g., between a common language level and a language independent level)
When a document is relevant across multiple languages or regions, Google can track user response rates across languages and countries to further refine relevancy:
To exploit language similarities, the rank refiner engine 1058 processes the document collection based upon the languages detected for each query and document pair. In this illustration, for one query/document pair, a collection of language data 400 is associated with four languages (e.g., English 402, German 404, Spanish 406 and Chinese 408). For each identified language, corresponding click data is also identified for this query/document pair. From this click data, the rank refiner engine 1058 produces a metric for comparing use of the document for each language. In this arrangement, a fraction (referred to as a click fraction) is calculated for each of the identified languages. Various types of fractions may be defined and used by the rank refiner engine 1058, for example, the click fraction may represent a ratio between the number of instances that the document was selected (for that respective language) and the total number of instances that the document was selected (for all of the languages).
If Google believes a searcher has a high or low probability of being able to understand a document in a foreign language, Google can factor that into how well it ranks those documents. If a particular language has a vastly different click distribution than other languages, its influence on results in other languages can be dampened or removed outright.
From Modifying Search Results Based on Populations...
Here are a couple images showing that they look at data from within common countries and languages and use it to adjust the search results.
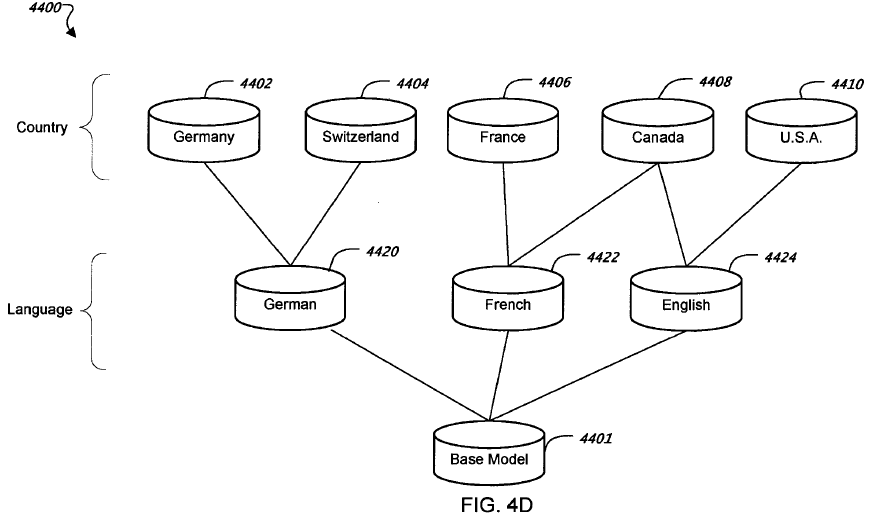
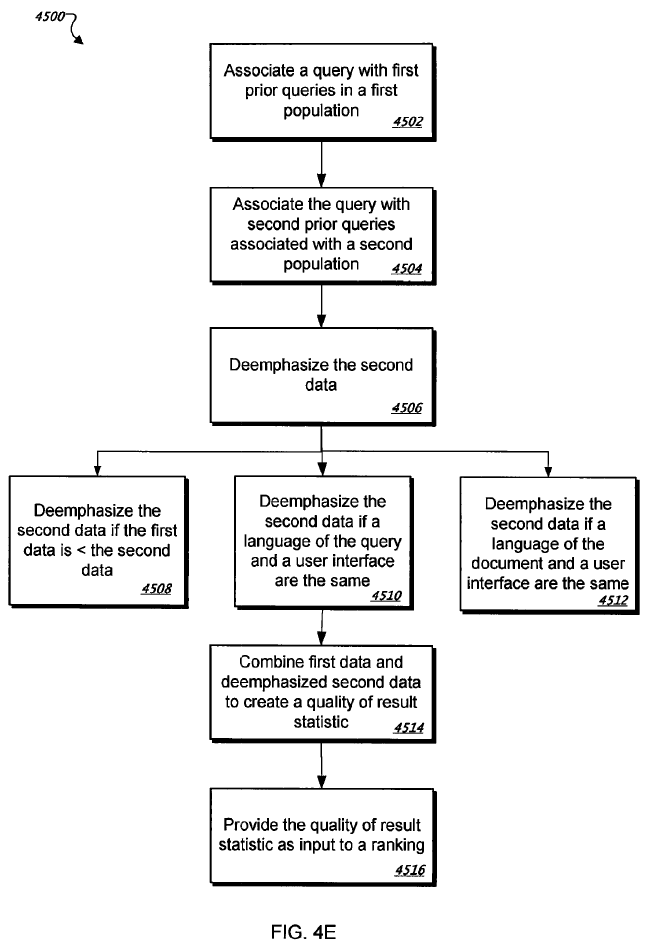
They try to use the more specific data when they can, but if the data is insufficient to have a high degree of confidence they can fall back on broader parallel markets or using global aggregate stats.
The click data stored in the databases 4400 can be used to calculate traditional and [long click count] LCC click fractions. The click data in the language, country and global databases can be used to modify a rank of a document in a search results list. If there is sufficient data in the country database, country-specific click data can be used. If there is not sufficient data (e.g., a small number of records) in the country database, data in the language database can be used. For example, for a given English query from Canada, if there is no data associated with that query in the Canada database 4408, there may be associated data in the English database 4424 (e.g., click data associated with the query may have come from clicks from another English-speaking country, such as the U.S.). If there is no data associated with a query in the country or language databases, there may be data associated with the query in the base model database 4401.
Individual documents which appear within the results can have their clickthrough data adjusted based on meeting minimum threshold criteria.
If the query has at least T1 clicks, it is determined whether the document has been shown at least T2 times on the first result page and has no country click data (step 4604). T2 is a threshold value, such as 10. If a document has not been shown very often on the first results page, there is a low probability that it will be clicked on, so deemphasizing click data (e.g., as in method 4500) is meaningful for documents that have been displayed at least a certain number of times on the first results page.
If the document has been shown at least T2 times on the first results page and has no country click data, it is determined whether the document has a language or global traditional click fraction that is above a threshold T3 (step 4606). If neither the language nor global traditional click fractions for a document are above a threshold value such as 0.1, then it may not be meaningful to deemphasize them (e.g., as in method 4500). If the document has a language or global traditional click fraction that is above a threshold T3, then a method providing an input to a ranking (e.g., method 4500) can be performed.
Localizing to the Wrong Location
Seeing irrelevant US-related sites ranking high in the UK search results might happen through traditional links-based relevancy signals, because the link graph around the United States is larger. But when the search results look like they are localized to a smaller country than the country being searched in (smaller population, lower internet penetration rate, fewer local websites, etc.), that indicates some other relevancy signals are being used.
As far back as 2009 David Naylor saw UK search results featuring sites primarily from Australia. Why would that happen? Well, the global bucket of click volume on [tennis court hire] was heavily dominated by Australian searches because the keyword was primarily searched for in Australia.
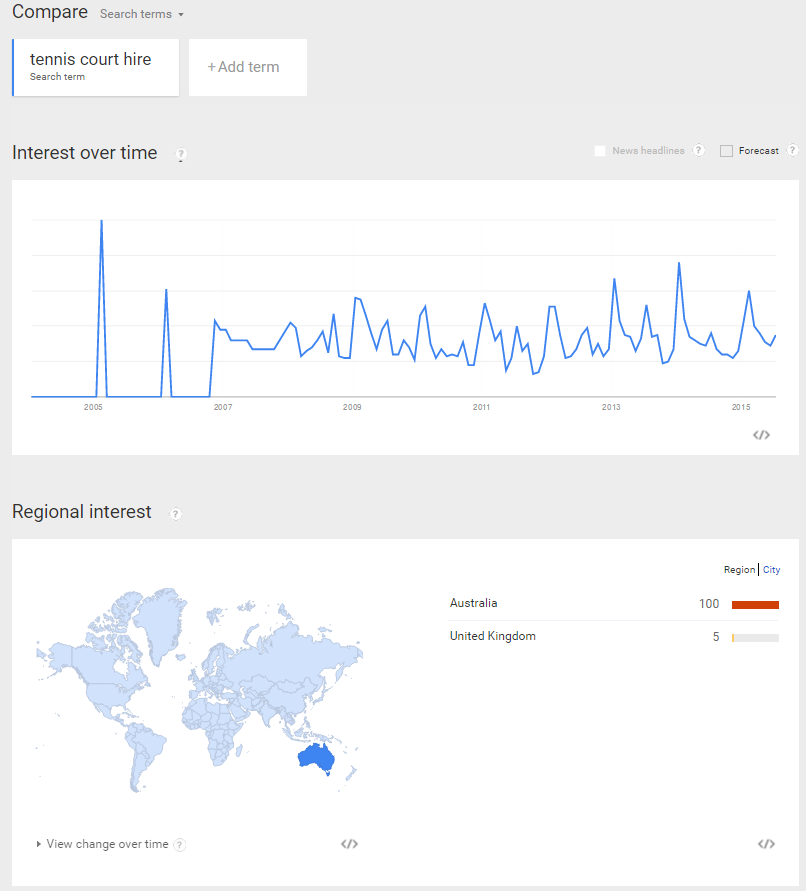
That means Google was folding in implicit ranking feedback from click data as far back as 2009. And it was happening across many different keywords.
In the time since then, Google has fixed the [tennis court hire, UK] search results, but are still bleed over impacts elsewhere.
While chatting with Cygnus about a year ago, we came across some US search results where the keywords were dominated by popular sites from the Philippines. When I pulled up Google Trends for the keyword it showed most of the search volume for that keyword was from the Philippines.
A more subtle example of localization bleed over happening across markets today would be [baby milk, US].
The query is popular in the UK.
Whatever ranks high in the UK and is well known gets a lot of clicks.
Tesco is like a UK localized equivalent of Walmart in the US. That UK ranked site with many clicks ends up ranking decent in the US, in spite of international shipping costs being prohibitive for most US-based consumers.
When I recently talked with a SEObook member he mentioned Google is still struggling with localization: ".com with an Austrian IP can be infuriating. If you search in English you get American results (not good for shopping obviously) but if you search in German you get German results (also not particularly good if you are looking for a new fridge/freezer for example)."
The pain searchers feel on those market edges are an opportunity for people who can optimize user experiences to suit searcher need in ways that the behemoths and scrape-n-displace plays miss.
Some Local Ideas
My wife and I recently stayed at a hotel which went out of their way to be remarkable. The hotel was also part of a school, so they did so many extras to teach their students hospitality. Here are just a few of the savvy marketing ideas they did:
- free local cell phone in each room: these phones not only allow you to make local calls, but if someone gets lost they might end up searching for directions to the hotel, increasing the search volume for the hotel. They also offered a free mini-bar, a free room upgrade, unique architecture, and numerous other perks which give people many reasons to mention them.
- Free Wi-Fi: they offered free Wi-Fi in each room. Once you logged in, the page they redirected you to was their Facebook page, which encourages travelers to discuss them on Facebook.
- automated TripAdvisor review sequence: after your stay, they have a review request email sent to you, which will post the review to TripAdvisor, which will allow them to punch above their weight in terms of total reviews.
And while a hotel has many integration points given that a person is staying there, other local businesses have a wide range of promotional options. Bars have ladies night & happy hours, bowling alleys have glow in the dark bowling where a strike with a certain colored head pin is worth a $x prize, coffee shops offer free Wi-Fi, etc. Almost any local business could in theory host various Meet Ups or find other ways to turn what would be a slow night into a busy one.
Historical Data
On December 31st of 2003 Google applied for a patent on Information retrieval based on historical data. When it was approved & discovered by SEOs it made waves.
It included aspects like...
incorporating document age or freshness as a ranking signal
some web site producers use spamming techniques to artificially inflate their rank. Also, "stale" documents (i.e., those documents that have not been updated for a period of time and, thus, contain stale data) may be ranked higher than "fresher" documents (i.e., those documents that have been more recently updated and, thus, contain more recent data). In some particular contexts, the higher ranking stale documents degrade the search results.
...
For some queries, older documents may be more favorable than newer ones. As a result, it may be beneficial to adjust the score of a document based on the difference (in age) from the average age of the result set. In other words, search engine 125 may determine the age of each of the documents in a result set (e.g., using their inception dates), determine the average age of the documents, and modify the scores of the documents (either positively or negatively) based on a difference between the documents' age and the average age.
...
In some situations, a stale document may be considered more favorable than more recent documents. As a result, search engine 125 may consider the extent to which a document is selected over time when generating a score for the document. For example, if for a given query, users over time tend to select a lower ranked, relatively stale, document over a higher ranked, relatively recent document, this may be used by search engine 125 as an indication to adjust a score of the stale document.
using a wide variety of historical data information
the history data may include data relating to: document inception dates; document content updates/changes; query analysis; link-based criteria; anchor text (e.g., the text in which a hyperlink is embedded, typically underlined or otherwise highlighted in a document); traffic; user behavior; domain-related information; ranking history; user maintained/generated data (e.g., bookmarks); unique words, bigrams, and phrases in anchor text; linkage of independent peers; and/or document topics. These different types of history data are described in additional detail below. In other implementations, the history data may include additional or different kinds of data.
comparing link volume data to document age
it may be assumed that a document with a fairly recent inception date will not have a significant number of links from other documents (i.e., back links). For existing link-based scoring techniques that score based on the number of links to/from a document, this recent document may be scored lower than an older document that has a larger number of links (e.g., back links). When the inception date of the documents are considered, however, the scores of the documents may be modified (either positively or negatively) based on the documents' inception dates.
looking at link growth rates & growth rate deviations
Consider the example of a document with an inception date of yesterday that is referenced by 10 back links. This document may be scored higher by search engine 125 than a document with an inception date of 10 years ago that is referenced by 100 back links because the rate of link growth for the former is relatively higher than the latter. While a spiky rate of growth in the number of back links may be a factor used by search engine 125 to score documents, it may also signal an attempt to spam search engine 125. Accordingly, in this situation, search engine 125 may actually lower the score of a document(s) to reduce the effect of spamming.
...
a downward trend in the number or rate of new links (e.g., based on a comparison of the number or rate of new links in a recent time period versus an older time period) over time could signal to search engine 125 that a document is stale, in which case search engine 125 may decrease the document's score. Conversely, an upward trend may signal a "fresh" document (e.g., a document whose content is freshrecently created or updated) that might be considered more relevant
...
The dates that links appear can also be used to detect "spam," where owners of documents or their colleagues create links to their own document for the purpose of boosting the score assigned by a search engine. A typical, "legitimate" document attracts back links slowly. A large spike in the quantity of back links may signal a topical phenomenon (e.g., the CDC web site may develop many links quickly after an outbreak, such as SARS), or signal attempts to spam a search engine (to obtain a higher ranking and, thus, better placement in search results) by exchanging links, purchasing links, or gaining links from documents without editorial discretion on making links, Examples of documents that give links without editorial discretion include guest books, referrer logs, and "free for all" pages that let anyone add a link to a document.
...
According to an implementation consistent with the principles of the invention, information regarding unique words, bigrams, and phrases in anchor text may be used to generate (or alter) a score associated with a document. For example, search engine 125 may monitor web (or link) graphs and their behavior over time and use this information for scoring, spam detection, or other purposes. Naturally developed web graphs typically involve independent decisions. Synthetically generated web graphs, which are usually indicative of an intent to spam, are based on coordinated decisions, causing the profile of growth in anchor words/bigrams/phrases to likely be relatively spiky.
...
One reason for such spikiness may be the addition of a large number of identical anchors from many documents. Another possibility may be the addition of deliberately different anchors from a lot of documents. Search engine 125 may monitor the anchors and factor them into scoring a document to which their associated links point. For example, search engine 125 may cap the impact of suspect anchors on the score of the associated document. Alternatively, search engine 125 may use a continuous scale for the likelihood of synthetic generation and derive a multiplicative factor to scale the score for the document
comparing how frequently ranked documents are updated
For some queries, documents with content that has not recently changed may be more favorable than documents with content that has recently changed, As a result, it may be beneficial to adjust the score of a document based on the difference from the average date-of-change of the result set. In other words, search engine 125 may determine a date when the content of each of the documents in a result set last changed, determine the average date of change for the documents, and modify the scores of the documents (either positively or negatively) based on a difference between the documents' date-of-change and the average date-of-change.
tracking historical click behavior for a keyword to determine if the results should be regularly updated
Another query-based factor may relate to queries that remain relatively constant over time but lead to results that change over time. For example, a query relating to "world series champion" leads to search results that change over time (e.g., documents relating to a particular team dominate search results in a given year or time of year). This change can be monitored and used to score documents accordingly.
looking for signals of a change in ownership
One way to address this problem is to estimate the date that a domain changed its focus. This may be done by determining a date when the text of a document changes significantly or when the text of the anchor text changes significantly. All links and/or anchor text prior to that date may then be ignored or discounted.
...
the domain name server (DNS) record for a domain may be monitored to predict whether a domain is legitimate. The DNS record contains details of who registered the domain, administrative and technical addresses, and the addresses of name servers (i.e., servers that resolve the domain name into an IP address). By analyzing this data over time for a domain, illegitimate domains may be identified. For instance, search engine 125 may monitor whether physically correct address information exists over a period of time, whether contact information for the domain changes relatively often, whether there is a relatively high number of changes between different name servers and hosting companies, etc. In one implementation, a list of known-bad contact information, name servers, and/or IP addresses may be identified, stored, and used in predicting the legitimacy of a domain and, thus, the documents associated therewith.
looking at the quality of ads on a site
search engine 125 may monitor time-varying characteristics relating to "advertising traffic" for a particular document. For example, search engine 125 may monitor one or a combination of the following factors: (1) the extent to and rate at which advertisements are presented or updated by a given document over time; (2) the quality of the advertisers (e.g., a document whose advertisements refer/link to documents known to search engine 125 over time to have relatively high traffic and trust, such as amazon.com, may be given relatively more weight than those documents whose advertisements refer to low traffic/untrustworthy documents, such as a pornographic site); and (3) the extent to which the advertisements generate user traffic to the documents to which they relate (e.g., their click-through rate).
using rank shifts to flag editorial reviews or algorithmic dampening
search engine 125 may monitor the ranks of documents over time to detect sudden spikes in the ranks of the documents. A spike may indicate either a topical phenomenon (e.g., a hot topic) or an attempt to spam search engine 125 by, for example, trading or purchasing links. Search engine 125 may take measures to prevent spam attempts by, for example, employing hysteresis to allow a rank to grow at a certain rate. In another implementation, the rank for a given document may be allowed a certain maximum threshold of growth over a predefined window of time, As a further measure to differentiate a document related to a topical phenomenon from a spam document, search engine 125 may consider mentions of the document in news articles, discussion groups, etc. on the theory that spam documents will not be mentioned, for example, in the news. Any or a combination of these techniques maybe used to curtail spamming attempts.
...
It may be possible for search engine 125 to make exceptions for documents that are determined to be authoritative in some respect, such as government documents, web directories (e.g., Yahoo), and documents that have shown a relatively steady and high rank over time. For example, if an unusual spike in the number or rate of increase of links to an authoritative document occurs, then search engine 125 may consider such a document not to be spam and, thus, allow a relatively high or even no threshold for (growth of) its rank (over time).
leveraging browser data
user maintained or generated data may be used to generate (or alter) a score associated with a document. For example, search engine 125 may monitor data maintained or generated by a user, such as "bookmarks," "favorites," or other types of data that may provide some indication of documents favored by, or of interest to, the user. Search engine 125 may obtain this data either directly (e.g., via a browser assistant) or indirectly (e.g., via a browser). Search engine 125 may then analyze over time a number of bookmarks/favorites to which a document is associated to determine the importance of the document.
...
other types of user data that may indicate an increase or decrease in user interest in a particular document over time may be used by search engine 125 to score the document. For example, the "temp" or cache files associated with users could be monitored by search engine 125 to identify whether there is an increase or decrease in a document being added over time. Similarly, cookies associated with a particular document might be monitored by search engine 125 to determine whether there is an upward or downward trend in interest in the document.
What is more interesting about that patent in comparison to the other ones I read while writing this article was just how heavily that patent referenced links in the examples. Anchor text and link-based criteria were 2 separate sections. They included 63 example implementations in the patent and dozens of them were about links. They most likely were not willing to put heavy emphasis on many of the usage data related signals until after they had a broad distribution of Chrome and Android.
Tracking Document Changes
Not only can Google leverage historical usage data to refine relevancy, but they recently had a patent approved on Modifying Ranking Data Based on Document Changes. The abstract reads:
Methods, systems, and apparatus, including computer programs encoded on computer storage media for determining a weighted overall quality of result statistic for a document. One method includes receiving quality of result data for a query and a plurality of versions of a document, determining a weighted overall quality of result statistic for the document with respect to the query including weighting each version specific quality of result statistic and combining the weighted version-specific quality of result statistics, wherein each quality of result statistic is weighted by a weight determined from at least a difference between content of a reference version of the document and content of the version of the document corresponding to the version specific quality of result statistic, and storing the weighted overall quality of result statistic and data associating the query and the document with the weighted overall quality of result statistic.
Here are a couple images from it.
The first shows how a document at a given location may change over time.

The second shows how Google may build a model of user experience data for specific URLs at different points of time.
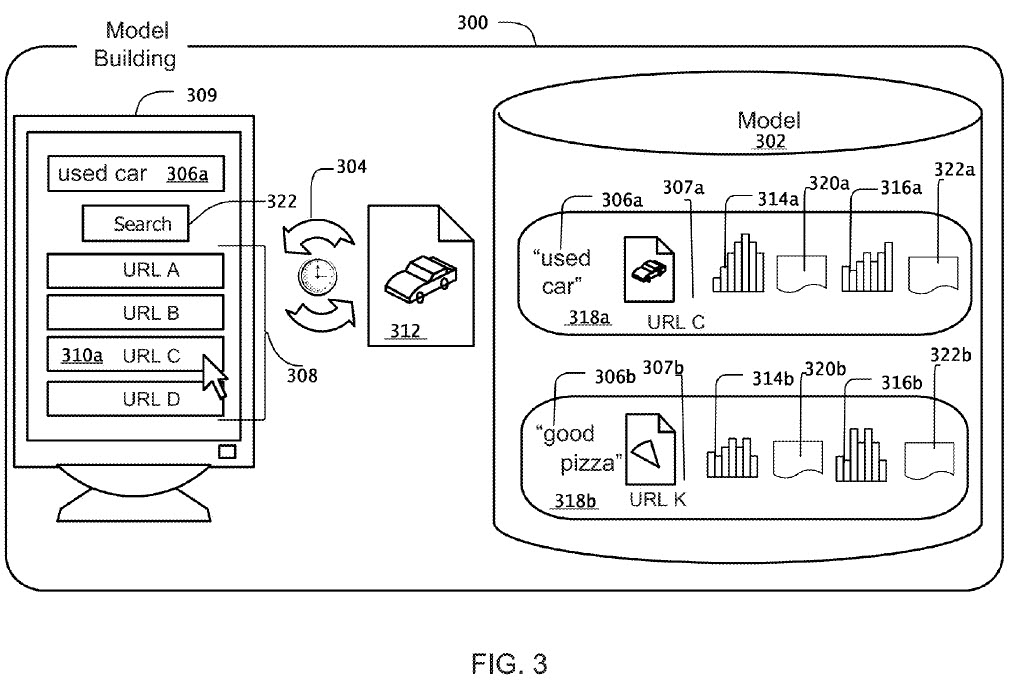
Rather than saying "people like URL x amount y" Google can compare the different versions of a document over time based on how similar they are using sliding shingles to determine if the page has changed much. If a document has only had minor changes they can rely heavily on the older historical information for that document, but if a document has a massive change Google could heavily discount older performance data and put more weight on how users engage with the current version of the document.
The ranking engine 210 ranks documents in response to user queries. One indicator the ranking engine uses is an overall quality of result statistic, which can be weighted or non-weighted as described in more detail below. A quality of result statistic engine 216 generates weighted overall quality of result statistics for query-document pairs and optionally generates non-weighted overall quality of result statistics for query-document pairs. Each query-document pair consists of a query and a document. The quality of result statistic engine 216 provides either the weighted overall quality of result statistics or the non-weighted overall quality of result statistics to the ranking engine 210
Google can put each version of a document in a different bucket and choose to weight the most recent versions most heavily.
The number of times the document changed subsequent to the time the historical version of the document was detected can serve as a proxy for the age of the document or the frequency with which a document is updated. Versions that are older or that are for a document that is updated more frequently since the historical version of the document was detected generally should have lower weights that versions that are newer or for a document that is updated less frequently since the historical version of the document was detected. Therefore, the larger the number of times the document changed since the version was detected, the lower the weight for version-specific quality of result statistics for the document version and the query should be.
If a page is constantly changing (like the homepage to a large news site) Google can use non-weighted metrics to avoid over-counting changes which are not significantly aligned with shifting relevancy.
Google can also look at how frequently the document changes as a signal of quality, by comparing how frequently a document changes against other documents ranking for the same term.
In some implementations, the system penalizes the weighted or non-weighted overall quality of result statistic for a given document and query when the given document does not change very much over time and other documents responsive to the given query, for example, the other documents with the highest overall quality of result statistics, do change over time.
If you have a few key pages which drive significant revenues and you see some fresher pages ranking better for the associated keywords, it may make sense to schedule some of those key pages for regular updates every year or every few years.
The performance data across a version of a document can also be granularized by location
the version-specific quality of result statistics stored in the model data are specific to a geographic location, e.g., a city, metropolitan region, state, country, or continent, specific to a language preference, or a combination of the two. Change can be measured, for example, as the frequency with which document content changes or the amount of content that changes. The amount of content can be measured, for example, by a difference score. For example, the system can determine whether the amount of change of the given document, either frequency of change or amount of content is low relative to the amount of change of other documents responsive to the given query. If so, the system can penalize the overall or non-weighted quality of result statistic for the given document and the given query, e.g., by reducing the value of the statistic.
Engagement Bait
Best Time Ever
If one is an optimist about techno-utopia, it is easy to argue there has never been a better time to start something, as the web keeps getting more powerful and complex. The problem with that view is the barrier to entry may rise faster than technology progresses leading to fewer business opportunities as markets consolidate and business dynamism slows down. Hosting is dirt cheap and Wordpress is a powerful CMS which is free. But the cost of keeping sites secured goes up over time & the cost of building something to a profitable scale keeps increasing.
Google is still growing quickly in emerging markets, but they can't monetize those markets well due to under-developed ad ecosystems. And as Google has seen their revenue growth rate slow, they've slowed hiring and scrubbed an increasing share of publisher ad clicks to try to shift more advertiser budget onto Google.com and YouTube.com. They've also ramped up brand-related bid prices in search (RKG pegged the YoY shift at 39% higher & QoQ at 10% higher). Those brand-bids arbitrage existing brand equity and people using last click attribution under-credit other media buys.
The Beatings Shall Go On...
Brands have brand equity to protect, which Google can monetize. So long as Google can monetize the brand-related queries, it doesn't hurt Google to over-represent brands on other search queries. It is a low-risk move for Google since users already have an affinity for the associated brands. And as Google over-promotes brands across a wider array of search queries, Google can increase the AdWords click costs on branded keywords for brands which want to protect their brand terms:
Several different marketing agencies are claiming the price of branded cost-per-click Google AdWords has ballooned by as much as 141% in the last four to eight weeks, causing speculation to swirl throughout the industry.
New sites are far riskier to rank. They have no engagement metrics and no consumer awareness. If Google ranks a garbage page on a brand site users likely blame the brand. If Google ranks a garbage smaller site users likely blame Google. Until you build exposure via channels other than organic search, it can be hard to break into the organic search market as Google increasingly takes a wait-and-see approach.
It is no secret that as Google's growth rate has slowed they've become more abusive to the webmaster community. Increasing content theft, increasing organic search result displacement (via additional whitespace, larger ad extensions, more vertical search types), more arbitrary penalties, harsher penalties, longer penalties, irregular algorithm updates, etc.
If you are not funded by Google, anything that can be a relevancy signal can also be proof of intent to spam. But those who have widespread brand awareness and great engagement metrics do not need to be as aggressive with links or anchor text to rank. So they have more positive ranking signals created through their engagement metrics, have more clean links to offset any of the less clean links they build, are given a greater benefit of the doubt on manual review, and on the rare chance they are penalized they recover more quickly.
Further, those who get the benefit of the doubt do not have to worry about getting torched by ancillary anti-revenue directives. A smaller site has to worry about being too "ad heavy" but a trusted site like Forbes can run interstitial ads, YouTube can run pre-roll ads, and The Verge can run ads requiromg a scroll to see anything beyond the welcome ad and the site's logo - while having a lower risk profile than the smaller site.

Bigger sites get subsidies while smaller sites get scrubbed.
The real risk for bigger players is not the algorithm but the search interface. While marketers study the potential impacts of a buy button on mobile devices, Google is quietly rolling out features that will allow them to outright displace retailers by getting information directly from manufacturers.
Rank Modifying Spammers
Google is willing to cause massive collateral damage to harm others and has been that way since at least 2005:
I was talking to a search rep about Google banning certain sites for no reason other than the fact that a large number of spammers where using that sTLD, well 1.2 million small business got washed down the plug hole with that tweak ! On the other side of the coin I discussed with Yahoo about banning sites, when they ban a site they should still list the homepage if someone typed in the url. Even if Yahoo thought that the site in question as complete waste of bandwidth, if a searcher wanted to find that site they should still be able to find it !! That’s a search engines job at heart to supply the public with relevant search results.
And one could argue that same sort of "throw the baby out with the bathwater" has not only continued with Panda false positives, pre-emptive link disavows, etc. but that it spanned all the way back to the Florida update of 2003.
On Twig Matt Cutts stated:
There are parts of Google's algorithms specifically designed to frustrate spammers and mystify them and make them frustrated. And some of the stuff we do gives people a hint their site is going to drop and then a week or two later their site actually does drop so they get a little bit more frustrated. And so hopefully, and we've seen this happen, people step away from the dark side and say "you know, that was so much pain and anguish and frustration, let's just stay on the high road from now on" some of the stuff I like best is when people say "you know this SEO stuff is too unpredictable, I'm just going to write some apps. I'm going to go off and do something productive for society." And that's great because all that energy is channeled at something good.
Both Bill Slawski and PeterD wrote about a Google patent related to "rank modifying spammers" named Ranking Documents. At the core of this patent is the idea that Google is really good at pissing people off, screwing with people, and destroying the ability of SEOs to effectively & profitably deliver services to clients.
The abstract from the patent reads:
A system determines a first rank associated with a document and determines a second rank associated with the document, where the second rank is different from the first rank. The system also changes, during a transition period that occurs during a transition from the first rank to the second rank, a transition rank associated with the document based on a rank transition function that varies the transition rank over time without any change in ranking factors associated with the document.
Here are a couple images from the patent. First an image of what a transparent & instantaneous rank adjustment might look like
![]()
And then a couple examples of alternative models of rank transition.
![]()
The basic problem Google has with instantaneous rank shifts is it would let "spammers" know what they are doing is working & effective. Whereas if Google puts in a bit of delay, they make it much harder to be certain if what was done worked. And, better yet (for Google), if they first make the rank drop before letting it go up, they then might cause people to undo their investments, revert their strategy, and/or cause communications issues between the SEO & client - ultimately leading to the client firing the SEO. This is literally the stated goal of this patent: to track how marketers respond to anomalies in order to self-identify them as spammers so they may be demoted & to cause client communication issues.
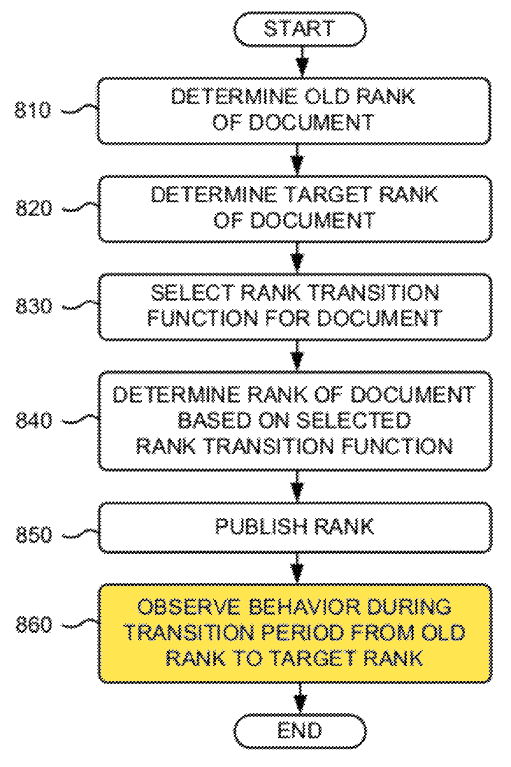
By artificially inflating the rankings of certain (low quality or unrelated) documents, rank-modifying spamming degrades the quality of the search results. Systems and methods consistent with the principles of the invention may provide a rank transition function (e.g., time-based) to identify rank-modifying spammers. The rank transition function provides confusing indications of the impact on rank in response to rank-modifying spamming activities. The systems and methods may also observe spammers' reactions to rank changes caused by the rank transition function to identify documents that are actively being manipulated. This assists in the identification of rank-modifying spammers.
The "noise" offered by the above process can also be mixed up to prevent itself from offering a consistent signal & pattern:
Based on the knowledge that search results are consciously being manipulated (e.g., frequently monitored and controlled) via rank-modifying spamming, search engine 430 may, as described in more detail below, use a rank transition function that is dynamic in nature. For example, the rank transition function may be time-based, random, and/or produce unexpected results.
And what happens during that noise period?
For example, the initial response to the spammer's changes may cause the document's rank to be negatively influenced rather than positively influenced. Unexpected results are bound to elicit a response from a spammer, particularly if their client is upset with the results. In response to negative results, the spammer may remove the changes and, thereby render the long-term impact on the document's rank zero. Alternatively or additionally, it may take an unknown (possibly variable) amount of time to see positive (or expected) results in response to the spammer's changes. In response to delayed results, the spammer may perform additional changes in an attempt to positively (or more positively) influence the document's rank. In either event, these further spammer-initiated changes may assist in identifying signs of rank-modifying spamming.
Think of the time delay in the above rank shift as being a parallel to keyword (not provided) or how Google sometimes stacks multiple algorithm updates on top of one another in order to conceal the impact of any individual update. And the whole time things are in flux, Google may watch the SEO's response in order to profile and penalize them:
the delayed and/or negative response to the rank-modifying spamming may cause the spammer to take other measures to correct it. For example, for a delayed response, the spammer may subject the document to additional rank-modifying spamming (e.g., adding additional keywords, tiny text, invisible text, links, etc.). For a negative response, the spammer may revert the document and/or links to that document (or other changes) to their prior form in an attempt to undo the negative response caused by the rank-modifying spamming.
The spammer's behavior may be observed to detect signs that the document is being subjected to rank-modifying spamming (block 860). For example, if the rank changed opposite to the initial 10% change, then this may correspond to a reaction to the initially-inverse response transition function. Also, if the rank continues to change unexpectedly (aside from the change during the transition period due to the rank transition function), such as due to a spammer trying to compensate for the undesirable changes in the document's rank, then this would be a sign that the document is being subjected to rank-modifying spamming.
Correlation can be used as a powerful statistical prediction tool. In the event of a delayed (positive) rank response, the changes made during the delay period that impact particular documents can be identified. In the event of a negative initial rank response, correlation can be used to identify reversion changes during the initial negative rank response. In either case, successive attempts to manipulate a document's rank will be highlighted in correlation over time. Thus, correlation over time can be used as an automated indicator of rank-modifying spam.
When signs of rank-modifying spamming exist, but perhaps not enough for a positive identification of rank-modifying spamming, then the “suspicious” document may be subjected to more extreme rank variations in response to changes in its link-based information. Alternatively, or additionally, noise may be injected into the document's rank determination. This noise might cause random, variable, and/or undesirable changes in the document's rank in an attempt to get the spammer to take corrective action. This corrective action may assist in identifying the document as being subjected to rank-modifying spamming.
If the document is determined to be subjected to rank-modifying spamming, then the document, site, domain, and/or contributing links may be designated as spam. This spam can either be investigated, ignored, or used as contra-indications of quality (e.g., to degrade the rank of the spam or make the rank of the spam negative).
Google can hold back trust and screw with the data on individual documents, or do it sitewide:
In one implementation, a rank transition function may be selected on a per-document basis. In another implementation, a rank transition function may be selected for the domain/site with which the document is associated, the server on which the document is hosted, or a set of documents that share a similar trait (e.g., the same author (e.g., a signature in the document), design elements (e.g., layout, images, etc.), etc.). In any of these situations, the documents associated with the domain/site/set or hosted by the same server may be subjected to the same rank transition function. In yet another implementation, a rank transition function may be selected randomly. In a further implementation, if a document is identified as “suspicious” (described below), a different rank transition function may be selected for that document.
Part of the "phantom update," which started on April 29th of 2015, appeared to be related to allowing some newer sites to accrue trust and rank, or relaxing the above sort of dampening factor for many sites. Google initially denied the update even happening & only later confirmed it.
So long as you are not in the top 10 results, then it doesn't really matter to Google if you rank 11, 30, 87, or 999. They can arbitrarily adjust ranks for any newer site or any rapidly changing page/site which doesn't make it to page 1. Doing so creates massive psychological impacts and communication costs to people focused on SEO, while it costs Google nothing & other "real" publishers (not focused primarily on SEO) nothing.
If you are an individual running your own sites & it takes 6 months to see any sort of positive reaction to your ranking efforts then you only have to justify the time delay & funding the SEO efforts to yourself. But if you are working on a brand new client site & it has done nothing for a half-year the odds of the client firing you are extremely high (unless they have already worked with you in the past on other projects). And then if the rankings kick in a month or two after the client fires you then the client might think your work is what prevented the site from ranking rather than it being what eventually allowed the site to rank. That client will then have a damaged relationship with the SEO industry forever. They'll likely chronically under-invest in SEO, only contact an SEO after things are falling apart, and then be over-reactive to any shifts during the potential recovery process.
The SEO game is literally dominated by psychological warfare.
Gray Areas & Market Edges
Many leading online platforms will advocate putting the user first, but they will often do the opposite of what they suggest is a best practice for others.
Google says stop pushing App downloads yet its own teams push apps using same "bad" designs. http://t.co/9Z3NeGbZxR pic.twitter.com/UzX9DbKn3x— Jeremy Stoppelman (@jeremys) July 24, 2015
Once an entity has market power it gets to dictate the terms of engagement. But newer platforms with limited funding don't have that luxury. They must instead go to a market edge (which is ignored or under-served by existing players), build awareness, and then spread across to broader markets.
- Yelp never would have succeeded if it launched nationwide or globally from the start. They started in the Bay Area, proved the model, then expanded.
- Mark Zuckerberg accessed some Harvard information without permission to seed his site. And Facebook was started on a dense college campus before spreading to broader markets.
- Social networks often look the other way on spam when they are smaller because usage and adoption metrics fuel (perceived) growth, which in turn fuels a higher valuation from venture capital investors. Then they later clean up the spam and take a hit shortly before or after they go public.
- Pinterest allowed affiliate links and then banned them overnight.
- PlentyOfFish was accused of scraping profile information from other dating sites.
- Uber and AirBnB didn't pay much attention to many local laws until after they had significant marketshare. AirBnB built much of their early exposure off of Craigslist.
- Reddit was able to grow to a huge scale by serving some sketchy markets like jailbait, racist stuff, and other "industries" which were not well served online. Then when the site attained serious scales the founders came back and were all about building policies to protect users & promoting the message that the site is not about free speech at any cost.
- Google's business model relied on violating Overture's search ad patents. When they were profitable and about to go public they gave Yahoo!/Overture some stock to settle the lawsuit. In mobile they violated patents, then bought and gutted Motorola to offset it.
- YouTube's founders fueled their early growth by uploading pirated video content. When the site attained serious scale Google signed deals with the music labels and implemented Content ID.
- Alibaba sold a lot of counterfeit goods & didn't push to significantly clean it up until after they were a publicly listed $200 billion company.
The above is not advocacy for crime, but rather to point to the fact that even the biggest successes online had to operate in gray areas at some point in order to create large ecosystems. If you are trying to build something from nothing, odds are fairly good you will have to at some point operate in a gray area of some sort. If not a legal gray area, then perhaps by not following some other entity's guidelines or terms of services. Some guidelines exist to protect people, but many of them exist purely for anti-competitive reasons. As you become more successful, someone will hate you & there is likely someone or something you will hate. There is always an enemy.
Almost nobody spends as much as Google does on lobbying. And almost no company in recent history has been sued as many times as Google has.
I wouldn't suggest one should try to manufacture signals without also trying to build something of substance, but if you are starting from scratch and build something of substance without pushing hard to create some of the signals the odds of it working out are quite low. In most cases, if you build it, they won't come - unless it is aggressively marketed.
Facts & Figures
Google published a research paper named Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources. Some SEOs who read that research paper thought Google was suggesting links could be replaced with evaluating in-content facts as a new backbone of search relevancy. Rather I read that paper as Google suggesting what websites they would prefer to steal content from to power their knowledge graph.
Including stats and facts in content are important. They make the content easy to cite by journalists & by other people who are quickly writing while wanting to have their content come across as well-researched rather than a fluffy opinion piece. And it makes it easier for people to repeatedly seek out a source if they know that source can give them a more in-depth background on a particular topic. For example, when I sometimes buy Japanese video games on Yahoo! Japan auctions through Buyee, I might get the localized version of the name from HardcoreGaming101.net or Wikipedia.org.
But facts alone are not enough. By the time something is an irrefutable fact, it's ability to act as a sustainable differentiator on its own approaches zero & parasites like Google scrape away the value. Google didn't have to bear the cost of vetting the following, but the person who did isn't cited.
And even in some cases where they are cited, much of the value is extracted.
Choose shoes wisely. ... pic.twitter.com/YLBtaHWare— Carl Hendy (@carlhendy) July 30, 2015
As much as we like to view ourselves as rational human beings, everyone likes some form of gossip. It is obvious sites like TMZ and PerezHilton.com trade in gossip and speculation. But that sort of activity doesn't end with celebrity sites. Most sites which are successful on a sustainable basis tend to go beyond facts. Think of your favorite sites you regularly read. My favorite blogs related to hobbies like collecting vintage video games and sports cards are highly opinionated sites. And on this site we present many facts and figures, but a large amount of the value of this site is driven by speculating the "why" behind various trends and predicting the forward trends.
And as mainstream media sources are having their economics squeezed by the web, even some of them are openly moving "beyond facts." Consider the following quote from Margaret Sullivan, the public editor from the New York Times:
I often hear from readers that they would prefer a straight, neutral treatment — just the facts. But The Times has moved away from that, reflecting editors’ reasonable belief that the basics can be found in many news outlets, every minute of the day. They want to provide “value-added” coverage.
A good example of their "value-added" coverage was an entirely inaccurate exposé on nail salons. Even the most trusted news organizations are becoming more tabloid by the day, with the success of tabloids being used as a "case study" of a model other news organizations should follow.
No Site is an Island
One of the key points from the Cluetrain Manifesto was Hyperlinks subvert Hierarchies. The power of the web is driven largely by the connections between documents.
Sites which don't cite sources (or do not link to them) are inviting searches to go back to Google and look for more information. And, quite often, that will happen through a short click (a negative user engagement signal).
When Google was collecting less end user data (or folding it into their relevancy algorithms less aggressively) trying to maximally monetize all traffic was a rational approach for a webmaster. You only had to get the traffic to your site. What the traffic did after it hit your site wasn't all that important beyond dollars and cents, so long as you had links as the proxy for relevancy. But in a world where engagement metrics are on an equal footing with links and short clicks can count against you, it can make sense to under-monetize some of your traffic and give users other potential destinations to seek out. Users who click forward into another site are not clicking back to the Google search results. They are long clicks and a win.
Bill Slawski reviewed a Google patent named Determining Reachability. The patent abstract reads:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for determining a resource's reachability score. In one aspect, a method includes identifying one or more secondary resources reachable through one or more links of a primary resource wherein the secondary resources are within a number of hops from the primary resource; determining an aggregate score for the primary resource based on respective scores of the secondary resources wherein each one of the respective scores is calculated based on prior user interactions with a respective secondary resource; and providing the aggregate score as an input signal to a resource ranking process for the primary resource when the primary resource is represented as a search result responsive to a query.
In essence, Google can look at the user interaction from search of resources linked to from your page & determine if those pages tend to get a high CTR and tend to have a significant number of long clicks. If the pages you link to have great engagement metrics from search then Google can boost the ranking of your site. Whereas if the pages you link to have poor engagement metrics you could rank lower.
The prior user interactions with the respective secondary resource can represent an aggregation of multiple users' interactions with the secondary resource. The prior user interactions with the respective secondary resource can include a median access time or a click-through-rate associated with the respective secondary resource.
The same sort of engagement metrics referenced elsewhere (high CTR, long dwell time) are core to this.
User interaction data are derived from user interactions related to the resource and resources accessible through the resource, e.g., click through rates, user ratings, median access time, etc. In some implementations, a resource's click-through-rate for a given period of time is derived from the number of times users have been provided with an opportunity to access the resource and the number of times users have actually accessed the resource. A simplified example for calculating the click-through-rate of a resource presented P times and accessed A times (aggregated over multiple user sessions) is expressed as the ratio of A/P.
And Google could look at the pages linked to from the pages that are linked to, taking a view down multiple layers.
The one or more scores include, for example, a reachability score (RS) computed by the resource reachability system 120. Generally speaking, an RS is a score representing a number of resources a user is likely to visit by traversing links from the initial resource and/or an amount of time a user is likely to spend accessing a resource that is responsive to a query, including other resources linked (e.g., by hyperlinks or other associations) to the resource. The other resources are referred to as secondary or children resources. Secondary resources include grandchildren or tertiary resources, relative to the initial resource, great-grandchildren resources, etc. In general, each of the resources accessible by traversing links from the initial resource is referred to herein as a secondary resource unless otherwise specified.
If the sites & pages which are linked to are deemed to be trustworthy then that enhances the reachability score ranking boost.
In some implementations, the resource reachability system 120 is tuned to exclude certain secondary resources in calculating reachability scores for each primary resource. For example, a trustworthiness score T indicates whether the resource is reliable (i.e., includes relevant information) based on prior user interactions and optionally, a quality measure of the resource, based on intrinsic features. User interactions indicating trustworthiness include, for example, long clicks, source of resource, etc.
...
Only the resources with a T measure exceeding a corresponding threshold measure are selected for use in determining the RS of the primary resource.
One of the interesting aspects of this patent is that while it covers typical text documents and web videos, it primarily uses videos in the examples throughout. In spite of primarily using video as the example, they still include some of the same concepts they do with text documents in terms of long clicks, short clicks, and dwell time.
In some implementations, a long click of a video occurs if the video is viewed in excess of a playback duration that defines threshold view time, e.g., 30 seconds. In some implementations, if the video resource is a video of less than 30 seconds duration, then a long click occurs if the entire video is viewed at least once during a session. Alternatively, if the video resource is a video of less than 30 seconds duration, then a long click occurs if the entire video is viewed at least twice during a session. As used herein, the term “view” means that the video is played back on a user device without interruption, e.g., without navigating to another web page, or causing the browser window in which the video is being played back to become an inactive window. Other definitions can also be used.
What is particularly interesting about this patent is indeed Google *did* implement something like this on YouTube, on March 15th of 2012. They changed YouTube's recommendation and ranking algorithms to instead go after total view time rather than a raw number of video views. This in turn harmed some of the eHow-lite styled video content producers which showed a spammy image still or a 10 second sports highlight filled with nonsensical looping or irrelevant commentary. However the algorithm shift vastly increased overall view time per session (by about 300%) & in turn allowed Google to show more ads.
Going back to the patent, ...
Particular implementations of the subject matter described in this specification can be implemented to realize one or more of the following advantages. A resource's reachability score may provide an indication of the amount of time a querying user is likely to spend accessing the resource and any additional resources linked to the resource. Such a score may be used in a scoring function to produce search results that improve user experience and potentially improve an advertiser's ability to reach the user.
ADDED: After finishing the initial version of this document, Bill Slawski reviewed another approved Google patent on using video watch time as a ranking signal. It was filed on March 6th of 2013. For a patent on a business process invention to be valid it has to be filed within a year of when that process was first used in commerce. Here is the general concept:
In general, the system boosts the score for a search result if users historically tend to watch the resource for longer periods of time, and may demote the score if users historically tend to watch the resource for shorter periods of time.
They can compare the watch time of the top ranked search result as a baseline to judge other results by. If something gets watched longer then it can get a ranking boost. If something is either rarely selected by end users and/or has a short watch time when selected, then it can get ranked lower.
They also state this watch time concept could be applied to other media formats like web pages or listening to audio files, and they could count the chain of subsequent user actions as being associated with the first "viewing session" unless the session has ended (based on indications like going back to the search results and clicking on another listing, or searching again for a different keyword).
The performance data can be collected at a granular level on a query-document pair basis, and even granularized further from there based on language or user location. Individual users can also have their typical watch times modeled.
Usage data tends to have a self-reinforcing bias to it. Google can normalize the data on older videos when analyzing newer videos by weighting recent (CTR & watch time per view) data or only looking at performance data since the new video got its first impression ranking for that particular keyword.
Google offers publishers a watch time optimization guide here & ReelSEO offers a more detailed guide here.
High Value Traffic vs Highly Engaged Traffic
In many cases traffic value and engagement are roughly correlated: people who really want something will walk through walls to get it.
However, there are many markets where the streams are distinctly separate. For example, some people might want quick answers to a question or to know the background and history around a subject. They might be highly interested in the topic, but have limited commercial intent at the time.
In the travel vertical hotel bookings are the prime driver of online publishing profits. But if you focus your site on hotels, no matter how fantastic your editorial content is, it is almost impossible to build enough awareness and exposure to beat established market leaders if you are a rough complement to them. If you don't own traffic distribution you are screwed.
Booking online flights is a far lower margin piece of travel. And yet a site like Hipmunk which eventually planned to monetize hotels still started on flights because it was easier to have a scalable point of differentiation by focusing on the user experience and interface design.
Smaller publishers might focus on other forms of travel or history related content and then cross-sell the hotels. Over the years in the community Stever has shared all sorts of examples in the forums on building strategies around locations or events or historical aspects of different regions.
When there was almost no barrier to entry in SEO you could just immediately go after the most valuable keywords & then build out around it after the fact. Now it is more about building solid engagement metrics and awareness off of market edges & then pushing into the core as you gain the engagement and brand awareness needed to help subsidize the site's rankings on more competitive keywords.
I Just Want to Make Money. Period. Exclamation Point!
Affiliates were scrubbed. Then undifferentiated unbranded merchants were scrubbed. Over time more and more sites end up getting scrubbed from the ecosystem for a real or perceived lack of value add. And the scrubbing process is both manual and algorithmic. It is hard to gain awareness and become a habit if the only place you exist along the consumer funnel is at the end of the funnel.
If a person designs a site to target the high value late funnel commercial search queries without targeting other queries, they may not have built enough trust and exposure in the process to have great overall engagement metrics. If a person learns of you and knows about you through repeated low-risk engagements then the perceived risk of buying something is lower. What's more, ecommerce conversion rates tend to be fairly low, especially if the merchant is fairly new and unknown. And not only do many ecommerce startups carry ads, but even many of the largest ecommerce sites with the broadest selections and lowest prices (like Amazon or eBay or Walmart) carry ads on them to expand their profit margins.
By targeting some of the ancillary & less commercial terms where they can generate better engagement metrics, a store / publisher can build awareness and boost the quality of their aggregate engagement metrics. Then when it comes time for a person to convert and buy something, they are both more likely to get clicked on and more likely to complete the purchase process.
Competing head on with established players is expensive. Some newer networks like Jet.com are burning over $5 million per month to try to buy awareness and build network effects. And that is with clicking through their own affiliate links to try to save money. In many cases items they are selling at a discount are then purchased at retail prices on competing sites:
Jet’s prices for the same 12 items added up to $275.55, an average discount of about 11% from the prices Jet paid for those items on other retailers’ websites. Jet’s total cost, which also includes estimated shipping and taxes, was $518.46. As a result, Jet had an overall loss of $242.91 on the 12 items.
Panda & SEO Blogs
When the web was new, you could win just by existing. This was the big draw of the power of blogging a decade ago. But over time feed readers died, users shifted to consuming media via social sites & it became harder for a single person to create a site strong enough to be a habit.
Search Engine Roundtable publishes thousands of blog posts a year & yet Barry was hit by the Panda algorithm. Why was his site hit?
- Many posts are quick blurbs & recaps rather than in-depth editorial features which become destinations unto themselves
- If you are aware of Barry's site and visit it regularly then you may know him and trust him, but if you are a random search user who hasn't visited his site before, then if you land on one of the short posts it might leave you wanting more & seeking further context & answers elsewhere. That could lead to a short click & heading back to Google to conduct another background research query.
- The broader SEO industry is going through massive carnage. Old hands are quitting the game, while newer people entering the field are less aware of the histories of some well established sites. Many people newer to the field who know less of its history prefer to consume beautifully formatted and over-simplified messaging rather than keeping up with all the changes on a regular basis.
- Another big issue is Barry almost turns some of his work into duplicate content (in terms of end user habits, rather than textual repetition). And by that I mean that since he works with Search Engine Land, much of his best work gets syndicated over there. That in turn means many of the better engagement-related metrics his work accrues end up accruing to a different website. Further, SEL offers a daily newsletter, so many people who would regularly follow SERoundtable instead subscribe to that SEL newsletter & only dip in and out of SER.
If SER was hit, why wasn't SEObook also hit? I don't blog very often anymore & much of our best content remains hidden behind a paywall. I don't go to the conferences or work hard to keep my name out there anymore. So in theory our site should perhaps get hit too if SER got hit. I think the primary reason we didn't get hit is we offer a number of interactive tools on our site like our keyword density tool and our keyword research tool. Some people come back and use these repeatedly, and these in turn bleed into our aggregate engagement metrics. We also try to skew longer & more in-depth with our editorial posts to further differentiate our work from the rest of the market. We are also far more likely to question Google spin and propaganda than to syndicate it unquestioned.
It sounds like after 10 months of being penalized SER is starting to recover, but if Google is false positive torching sites with 10,000 hours of labor put into them, then so many people are getting nailed. And many businesses which are hit for nearly a year will die, especially if they were debt leveraged.
Engagement as the New Link Building
A lot more people are discussing brand engagement. Here's a recent post from Eric Enge, an audio interview of Martinibuster, and a Jim Boykin YouTube video on brand awareness and search engagement related metrics.
Guys like Martinibuster and Jim Boykin went out of their way to associate themselves with links. And now they are talking engagement.
And people like Nick Garner have mentioned seeing far more newer sites rank well without building large link profiles.
How Engagement is Not Like Links
If you create a piece of link bait which is well received the links are built & then they stick. No matter what else you do, many of those links stick for years to come.
User engagement is an ongoing process. It isn't something which can easily be bolted on overnight in a one-time event. If a site stops publishing content its engagement metrics will likely fall off quickly.
And things which are easy to bolt on will be quickly bolted onto by search engines themselves to keep people within the search ecosystem. Here's a quote from Baidu's CEO Robin Lee:
Do you see yourself more as an e-commerce company than a search company?
It’s very hard to differentiate those two. Search was the facilitator for commerce. But in the mobile age, we have to do a closed-loop action, not just a query. So, it’s more of a combination now.
It is easy to use the advice "create engaging content" but in reality sometimes the engagement has to come from the core of the business model rather than being something which is bolted onto a site in a corner by a third party marketer. Many consumer benefits (price, speed, variety) apply across markets. But some of them are specific to knowing your market well and knowing what people really care about. This applies to search as much as any other market. See Google's focus on speed & mobile, or this story on the fall of Lycos:
In our ongoing efforts to make search results better, Dennis set up an eye-tracking lab and began scientific testing of how people used search. We watched where people looked on the pages and noticed something shocking: people didn’t look at the ads. Not only that, but the more we tried to make the ads stand out, the less people looked at them. Our entire advertising philosophy was based on making ads flashy so people would notice them. But we saw, quite counterintuitively, that people instinctively knew that the good stuff was on the boring part of the page, and that they ignored the parts of the page that we—and the advertisers—wanted them to click on.
This discovery would give us an edge over everyone in the industry. All we had to do was make the ads look less like ads and more like text. But that was not what the ad people wanted, and the ad people ran Lycos.
There are even some sorts of sites where people *expect* there to be a bit of a delay & a "working" message, and trust a site less if the results are shown too quick. But such outliers are hard to know in advance & are hard to predict unless you know the market and the psychology of the user. Each market is every bit as unique & absurd as the following terrible logo.

The problem with creating an engaging site is it is quite hard to just bolt it on. To offer an interactive service which compels people to repeatedly use it you typically need to know the market well, need to know pain points, need to know points of friction, need a good idea of where the market is headed, need to have programmers (and perhaps designers) on staff, and you need to keep investing in creating content and marketing it.
If you have passion for a market it is easy to have empathy for people in the market and it is easy to predict many types of changes which will happen in the market. If you don't have passion for a market and want to compete in a saturated market then there is a lot of pain ahead.

Like it or not, the chunk size of competition is increasing:
Closed platforms increase the chunk size of competition & increase the cost of market entry, so people who have good ideas, it is a lot more expensive for their productivity to be monetized. They also don't like standardization ... it looks like rent seeking behaviors on top of friction
One of my favorite sites in terms of highlighting how a small team can create a bottoms up marketplace through knowing the market better than others and incrementally investing in the product quality is the collectible website Check Out My Cards / COMC.com. Off the start when they were newer they had to charge a bit more for shipping, but as they became larger they kept lowering costs and adding features. Some of their compelling benefits include...
- meticulous & correct product labeling, with multiple versions of the card side-by-side (which encourages vendors to lower prices to get the sale)
- centralized inventory and payment processing (which reduces the need for seller and buyer reputation scoring)
- fantastic site search & sorting options (by date, price, player, set, print run, popularity, team, percent off, recently added to the site, etc.)
- high resolution images of items (this allows sellers to justify charging different prices for the same inventory, allows buyers to see what copies are in the best shape and might be worth grading, and allows the site to create embeddable widgets which can be embedded in other sites linking back to the source)
- flat price listings along with the ability to negotiate on pricing
- standardized bulk low-cost shipping
- the ability to drop off cards for inclusion in the marketplace at large card shows
- the ability for buyers to leave things stored in the warehouse until they want them shipped, or being able to relist them for sale (which allows people to track hot players and changes in market demand to buy up inventory and hold it for a bit as the price goes up)
- they licensed card price data from Beckett for years & then created custom pricing catalog information based on prior sales throughout the history of the site
- etc.
When I looked up COMC on SimilarWeb only 19.52% of their overall traffic came from the search channel. The other 80% of their traffic gets to leave trails, traces & clues of user trust - relevancy signals which bleed over into helping search engines boost their organic search rankings.
And, as good as those hundreds of thousands of monthly regular direct users are, even much of the "search" traffic for the site is brand-related reference queries.
If most of your traffic is direct or via your own brand term that limits the downside impact Google can have on your business. To hurt you and not rank you for your branded keyword terms they have to hurt themselves. COMC only has a few hundred unique linking domains, but if they ever seriously approached link building with featured editorials based on stats from their marketplace and the sports they follow, they would have amazing SEO success.
Another collectible site I like is Price Charting. It focuses on video game prices. The have great sorting features, historical pricing charts, downloadable buying guides, custom game images which can be purchased in bulk and downloaded, a deal hunter tool which allows you to track eBay for new listings or auctions near their close where items are well below their normal retail price, and a blog covering things like rare games for sale and how to tell real games from fakes, etc.
The bigger sites like Amazon and eBay have lots of network effects behind them. And then Amazon is known for buying vertical sites to increase their share in the vertical (Audible.com, Zappos, etc.), drive informational searchers toward commerce (IMDB), or differentiate the Amazon.com buying experience (DPReview).
When you compete against Amazon or eBay you are not only competing against their accumulated merchant and product reviews, but also the third party ecosystem around them including their broad array of affiliates and other third party tools built around their data & service like Price Charting or bid snipers like Gixen or JBidWatcher. If you focus exclusively on the commercial keywords & want to launch a horizontal marketplace it is hard to have a compelling point of differentiation.
But if you go to a market edge or focus on a small niche (say a service like Buyee offering international shipping on Yahoo! Japan auctions) you can differentiate enough to become a habit within that market.
COMC stands for "check out my collectibles." Originally it stood for "check out my cards" which was the original domain name (CheckOutMyCards.com) before it was shortened to COMC.com. They planned on expanding the site from cards to include comics and other collectibles. But when Beckett terminated licensing their pricing catalog, COMC retrenched and focused on improving the user experience on sports cards. They have continued to add inventory and features, taking share away from eBay in the category. They've even tested adding auctions to the site.
Change the Business Model
The reason COMC is able to keep taking share away from eBay in the baseball card market is they remove a lot of friction from the model. You don't pay separate shipping fees for each item. You don't have to wait right until an auction is about to end. You don't have to try to estimate condition off of lower resolution pictures. Other businesses in the past couldn't compete because they had to carry the inventory costs. As a marketplace there is limited inventory cost & much of those costs are passed onto the sellers.
The other big theme played out over and over again is taking something which is paid (and perhaps an intensive manual process) and finding a way to make it free, then monetize the attention streams in parallel markets. Zillow did this with their Zestimates & did it again by offering free access to foreclosure and pre-foreclosure listings.
TV commercials for years informed consumers of the importance of credit reports and credit scores. Then sites use the term "free" in their domain names, when really it was perhaps a free trial tied to a negative billing option. Then Credit Karma licensed credit score data & made it free, giving them a valuation of $3.5 billion (which is about 10X the value of Quinstreet and 3X the value of BankRate).
Plenty of Fish was a minimalistic site which entered a saturated market late, but through clever marketing and shifting the paid business model to free the market leader had to pay Markus Frind over a half-billion dollars for the site in a defensive purchase.
Put Engagement Front and Center
In some cases an internal section of a site takes off and becomes more important than the original site. When that happens it can make sense to either shift that section of the site to the site's homepage, over-represent that section of the site on the homepage, or even spin that section out into its own site. For example, our current site had a blog on the homepage for many years. That blog was originally an internal page on a different website, and I could see the blog was eclipsing the other site, so I created this site while putting the blog front and center.
When you own a core position you can then move the site into the ancillary and more commercial segments of the market. For example, Yahoo! Sports is a leader in sports, which allowed them to then move into Fantasy Sports & eventually into paid Fantasy Sports. And when launching new sections within their verticals, Yahoo! can get over the chicken-vs-egg problem by selling ad inventor to themselves. Look at how many Yahoo! Fantasy sports ads are on this page.
For just about anyone other than ESPN, it would be hard to try to create a Yahoo! Sports from scratch today. ESPN's parent Disney intended to invest in a fantasy sports gambling site, but backed away from the deal over image concerns. The two biggest pure plays in fantasy sports are Draft Kings & Fan Dual, with each recently raising hundreds of millions of dollars. A majority equity stake in the #3 player DraftDay was recently sold for $4 million.
The sort of strategy of putting something engaging front and center can apply to far more established & saturated markets. And that in turn can act as an end around entry into other more lucrative markets. If Draft Kings and Fan Dual each have valuations above a billion dollars (and they do) and the #3 player is valued (relatively) at about the price of a set of steak knives, what's another approach to entering that market?
One good approach would be creating a stats site which has many great ways to slice and dice the data, like Baseball-Reference.com or Fan Graphs. Those stats sites get great engagement metrics and avail themselves to many links which a site about gambling would struggle to get.
Some of the data sources license paid data to many other sites & some provide data free. So if many people are using the same source data, then winning is mostly down to custom formatting options or creating custom statistics from the basic statistic packages & allowing other sites to create custom embeds from your data.
The cost of entry for another site is quite low, which is why players like FindTheBest have created sites in the vertical. Notice PointAfter is growing quickly, and this is after FindTheBest itself cratered.
That's because the sports stats are more interesting and engaging to sports fans than the random (and often incorrect! set of "facts" offered on the overly broad FindTheBest site). The same formula which failed on FindTheBest (aggressive link building, data embeds, scraped duplicate content, auto-generated QnA pages, etc.) can succeed on PointAfter because people are passionate about sports.
I probably wouldn't recommend being as aggressive as FTB is with auto-generating QnA pages and the like (unless one is funded by Google or has other important Google connection), but the efficacy of a formula depends as much on the market vertical as the underlying formula.
As the stats sites get more established, they could both add affiliate links for fantasy sports sites (likeso), and they could add their own "picks" sections or custom player valuation metrics. Eventually they could add news sections & if they had enough scale they could decide to run their own fantasy sports gaming sections.
In Closing
I am not sure there is an easy or logical place to end an article like this. It started with reading a couple patents & trying to put panda and clickstream data usage into the broader context on its impact on web publishing and online business models. But as I read one patent it led to the next & whenever I got down to 1 or 2 left somehow another related topic or theme would come up. I still have a list of about 20 more patents I want to read, but didn't want to wait until this article was 400 pages long to hit publish. ;)
Almost from day 1 I have been long on loving the link juice. It was one of the reasons I got off to a quick start with SEO back when the relevancy algorithms were less complex, as links were the proxy for the random surfer. Get links. Win. ;)
But today it is becoming far harder to win with an excessive emphasis on links & little other marketing done. In an age where Google has the leading marketshare in web browsers, mobile OS, and is pushing to offer "free internet" to entire countries, they have enough end user data to count it as much or more than they count links.
Usage data can certainly be spoofed just like links can. But Google is even tracking foot traffic with Android. So there is no guarantee spoofing it will be easy for an extended period of time, especially if it is done almost in isolation. And even if spoofing is successful, if the site then has terrible engagement rankings after it gets a top rank, those wins will be short lived.
We've moved away from relevancy + links = rank to awareness + popularity = rank.
In light of that shift, I think it is easy to get overwhelmed by the complexity of search and frozen by analysis paralysis or frozen by fear. However, the person who is out making a bit of noise every day & is focused on trying to build awareness will eventually end up building the engagement metrics Google leverages in their ranking algorithms.
A person who is great but is waiting on "if you build it, they will come" will typically end up disappointed in their outcomes. But so long as a person is receptive to feedback and is an aggressive push marketer, success has a good chance of coming.
Radiohead has a documentary named Meeting People is Easy. On the inside flap is the following quote, which I think is relevant to anyone playing the underdog roll in online marketing:
If you have been rejected many times in your life, then one more rejection then one more rejection isn't going to make much difference. If you're rejected, don't automatically assume it's your fault. The other person may have several reasons for not doing what you're asking her to do: none of it may have anything to do with you. Perhaps the person is busy or not feeling well or genuinely not interested in spending time with you. Rejections are part of everyday life. Don't let them bother you. Keep reaching out to others. Keep reaching out to others. When you begin to receive positive responses, then you are on the right track. It's all a matter of numbers. Count the positive responses and for get about the rejections.

